머신러닝
→ 인공지능이 스스로 똑똑해질 수 있게 만드는 기술
→ 데이터를 통해 컴퓨터가 '학습'을 하고 자동으로 문제를 해결
→ 데이터에서 일정한 규칙을 찾아내고, 이를 바탕으로 다른 데이터를 분류하거나 미래를 예측
1. 머신러닝의 유형
머신러닝의 대표적인 세 가지 유형
- 지도학습 : 훈련 데이터에 정답(Label)이 있어 주어진 정답에 맞게 특징이 학습되기를 기대하는 경우에 사용
- 비지도학습 : 훈련 데이터에 정답이 없고 주어진 특징 내에서 분류간 서로 구분이 잘 되도록 원하는 경우에 사용
- 강화학습 : 학습(혹은 수집)되는 데이터에 정답은 없으나 동작하거나 반응하는 결과에 상과 벌을 주어서 스스로 진화할 수 있는 경우에 사용
아래의 그림은 머신러닝의 기술 유형을 나타낸다.

* 이 책에서는 강화학습을 제외하고 지도학습과 비지도학습만 다룬다.
[지도학습 이해하기]
- 과거의 데이터로 미래 이벤트를 예측해야 하는 경우에 주로 사용
(ex : 신용카드 부정거래 여부, 보험 가능 여부 예측) - 학습 시 라벨 데이터가 미리 있어야 한다는 점이 가장 중요
- 라벨 값과 관계 없이 특징이 추출되며 이후 라벨 값이 추가되어 모델을 학습
- 추출된 특징 값은 라벨 값에 따라 특징들의 가중치가 조절됨 → 라벨에 최적화하도록 학습
아래 그림은 지도학습의 처리 절차를 나타냄.
-분류(Classification)-
- 이진 분류(Binary Classification) : 두 개의 군집으로 나누는 것
텍스트 분석일 경우 : 긍정과 부정을 구분하는 감정 분석에 활용 - 다중분류(Multi Classification) : 세 개 이상의 군집으로 나누는 것
텍스트 분석일 경우 : 토픽 모델링
이미지 분석일 경우 : 이미지 태깅
-회귀(Regression)-
훈련 데이터의 값을 분석해 주어진 값에 대한 결과 수치를 예측하는 것 → 최적의 예측 함수를 찾는 것
[비지도학습 이해하기]
- 입력에 대한 정답이 없으며 데이터만을 통해 학습을 수행 → 데이터 자체에서 유용한 패턴을 찾아내는 학습 방법
- 정답을 찾기보다는 분류를 통해 역으로 특성을 파악하고 답에 접근하는 방법
아래 그림은 비지도학습의 처리 절차를 나타냄.
-군집화(Clustering)-
- 특징이 비슷한 데이터끼리 묶는 방법
-차원 축소(Dimension Reduction)-
- 특성이 많은 데이터를 특징의 수를 줄이면서 꼭 필요한 특징을 포함한 데이터로 표현하는 방법
2. 의사결정나무(Decision tree)
- 데이터 분포를 나누는 지도학습의 분류에 해당하는 모델
- 스무고개 게임처럼 연속적인 질문을 통해 예측 결과를 제공하는 예측 모델
- 사람이 조건에 따라 행동하고 판단하는 것을 응용한 모델
[의사결정나무의 특징]
- 결과 해석 용이
- 처리 결과를 해석하기가 쉬움.
- 모델을 이용하여 데이터를 예측하는 경우도 있고 분류되는 과정에서 분류 기준이 되는 중요한 아이템을 발견할 가능성도 있음
- 수치형, 범주형 데이터 모두 적용 가능
- 다양한 데이터 형식에 사용이 가능함
- 전처리 비용 적음
- 의사결정나무는 분할 지표로 사용되기 때문에 데이터 전처리에 따른 작업이 훨씬 수월해짐
- 과적합 가능성 높음
- 부정적인 특징
- 훈련용 데이터를 검토하여 이상값이나 예외값을 정제하는 등의 대첵이 필요함
[의사결정나무의 대표 알고리즘]
의사결정나무에는 분석을 위한 알고리즘으로 ID3, C4.5, CART, CHAID 등이 있음
여기서 가장 자주 사용되는 두 가지 알고리즘 CART와 C4.5에 대해 살펴봄
- CART(카트)
- 가장 잘 알려진 방법론 중 하나
- 1984년 레오 브레이만이 기법을 발표
- 지니 계수(범주형 변수) 또는 분산의 감소량(연속형 변수)을 사용해 나무의 가지를 이진(Binary) 분리
- C4.5(C5.0)
- 1986년에 로스 쾬란이 발표한 ID3을 개량, 발전시킨 모델
- 분할의 평가 기준으로 이득 비율(gain rain)을 이용
- CART와 달리이진 분류에 국한되지 않으며 세 가지 분기까지 가능
***의사결정나무 실습해보기
1. iris 데이터 분류
#개발환경
#운영체제 : 윈도우 7 이상
#개발 플랫폼 : 파이선 3.6 이상
#주요 패키지 : 넘파이(NumPy) 1.6 이상, 사이파이(SciPy)0.9 이상, 사이킷런(Scikit-Learn)0.19이상
import sys
import numpy as np
import scipy as sp
import sklearn
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
def main () :
# iris 데이터 로드 (1)
dataset = datasets.load_iris ()
features = dataset.data
targets = dataset.target
# 꽃잎의 길이와 넓이 정보만 특징으로 사용 (2)
petal_features = features [:, 2 :]
# 의사결정 모델 클래스 생성 (3)
cIris = DecisionTreeClassifier (criterion = 'entropy' , max_depth = 3 )
#모델을 훈련 (4)
cIris.fit (petal_features, targets)
# DOT 언어의 형식으로 결정 나무의 형태를 출력한다.
with open ( 'iris-dtree.dot' , mode = 'w' ) as f :
tree.export_graphviz (cIris, out_file = f)
if __name__ == '__main__' :
main ()
실행 결과 :
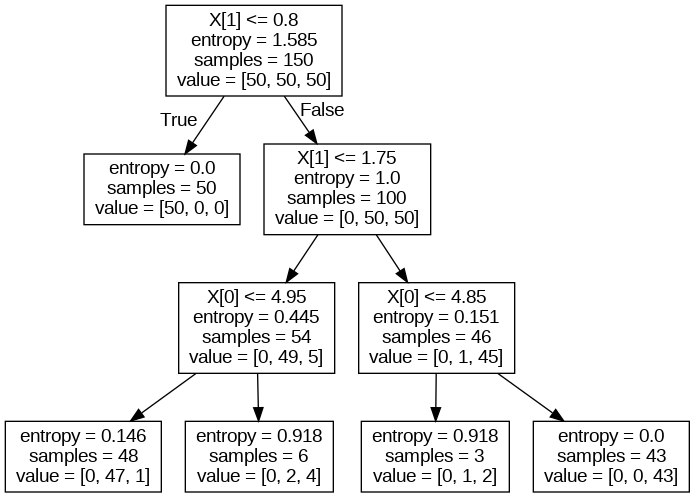
*이미지는 dot 파일을 cmd창에서 [dot -T png iris-dtree.dot -o iris-dtree.png] 명령어를 통해 이미지로 변환해주어야함!
<의사결정나무 알고리즘의 처리 흐름 정리>
- 분류에 필요한 파이썬 모듈과 데이터 세트 준비
- 분석할 데이터 세트의 특성(데이터 특징, 레이블, 내용) 확인 및 학습 및 검증용 데이터 분할
- 의사결정나무의 변수 조정
- 모델 내용 시각화
3. 서포트 벡터 머신 알고리즘(Support Vector Machine)
- 데이터 분포를 나누는 분류 모델
- 1963년 러시아 수학자 블라디미르 배프닉과 알렉세이 체보넨키스에 의해 발표됨
- 1992년 블라디미르 배프닉에 의해 비선형으로 확장
- 데이터를 선형 또는 비선형으로 분리하는 최적의 경계를 찾는 알고리즘
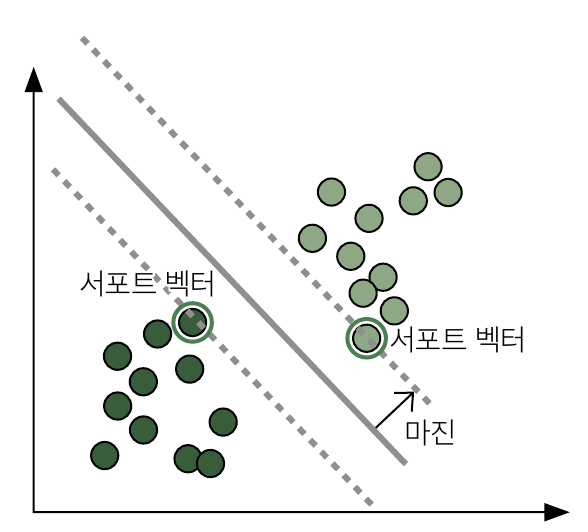
[서포트 벡터 머신의 동작 원리]
아래의 데이터를 예로 들자.
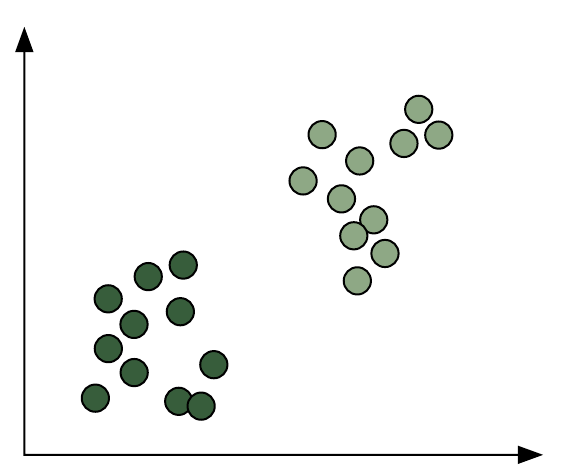
1. 직선을 그어 그룹을 나눈다.
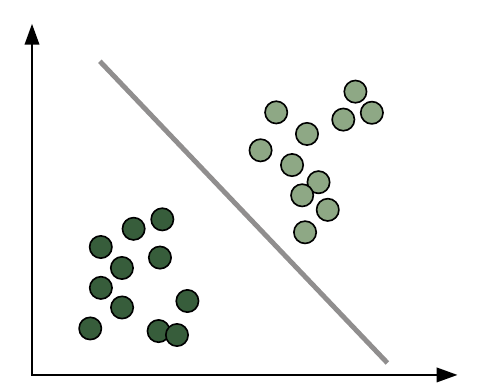
2. 마진을 최대화하여 균형 있게 나눈다.
균형 있게 나누기 위해 직선식을 사이에 두고 최대한 멀리 떨어지도록 점선을 구함
**점선에 속한 점이 직선을 침범하지 않도록 만드는 안전지대 역할을 하고, 버팀대 또는 지지대 역할을 한다 해서 서포트 벡터(Support Vector)라고 부름
**이 점선과 직선의 사이를 최대 마진이라고 함.
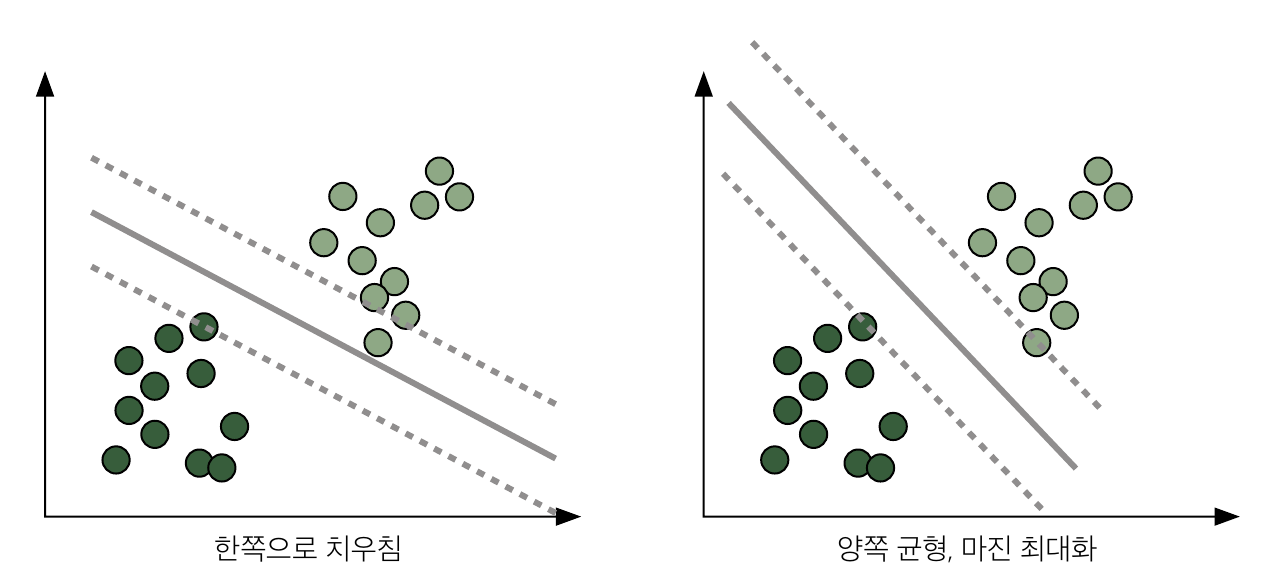
훈련이 진행되면서 최적의 경계를 찾게 됨.
마진이 최대가 되도록 직선을 조정하여 분류 간 최대로 분리시키는 것이 서포트 벡터 머신이 추구하는 기본 사상임.
'정리 > 실무가 훤히 보이는 머신러닝&딥러닝' 카테고리의 다른 글
| 6장_텐서플로를 이용한 이미지 객체 추출 (0) | 2023.03.02 |
|---|---|
| 5장_딥러닝을 이용한 이미지 분류 (0) | 2023.02.28 |
| 4장_비지도학습을 이용한 군집화 (0) | 2023.02.27 |
| 2장_인공지능을 적용하기 위한 방법 (2) | 2023.02.06 |
| 1장_인공지능이란 무엇인가 (0) | 2023.02.02 |



