[Introduction]

특정 작업에 초점을 맞춘 스마트폰 애플리케이션이 증가함에 따라 모바일 컴퓨팅은 대도시에서 인간 활동을 연구하는데 매우 중요하다.
이를 연구하기 위해 사용할 수 있는 수단 중 사용자 생성 콘텐츠는 개인을 글로벌 규모의 센서로 활용하여 공간 참조 데이터를 수집하는 데에 사용할 수 있는 영향력 있는 수단이다.
본 논문에서는 트위터에서 트래픽 관련 이벤트를 지오코딩하는 방법론을 제안하며 시공간 분석을 통해 교통체증 시공간 정보를 제공한다.
교통 관련 이벤트의 공간 분포는 Web-GIS 애플리케이션에서 교통 혼잡의 집중 또는 밀도를 설명하는 히트맵으로 표시하며 정밀도 및 재현율을 통해 평가를 수행하였다.
[Method and Materials]
본 논문의 전체구조도로 총 8단계로 이루어져있으며 1-6단계는 지오코딩 프로세스 단계이며 7-8단계는 예측모델 생성 및 시각화 단계이다.
- Geocoding Traffic‐Related Events from Tweets
거리, 대중교통 정류장, 지역과 같이 트위터에서 지리적 요소를 검색하려면 수동 및 자동 단계의 조합이 필요하다.
때문에 geoname을 사용한다.
geoname이란 사용자가 편집이 가능한 지리적 데이터베스를 말하며 다양한 언어로 이루어져있다.
데이터베이스에는 장소이름, 위도, 경도, 고도, 인구, 행정구역, 우편번호가 존재한다.
- Data Acquisition and Information Analysis
식별 가능한 데이터를 모은 데이터셋을 통해 가장 자주 사용되는 단어를 계산하는 알고리즘을 구현하였다.
- Creation of the Dictionaries and Equivalents
멕시코 국립통계지리연구소 수치를 통해 일부 용어집을 생성하여 사전을 풍부하게 만들었으며 지상요소를 치수적으로 표현하는데 필요한 지리적 특징을 "G" 문자를 통해 식별한다.
또한 도로는 하나 이상의 이름으로 표현이 가능하기 때문에 동등한 위치를 나타내는 여러 단어를 용어집으로 만들었다.
- Gazetteer Division
정보 분석에 따르면 일반적으로 일부 거리에서 가장 많은 유입 관련 이벤트가 발생하기 때문에 게시판은 두 부분으로 나눈다. 첫번째는 게시판에 존재하는 트윗에서 자주 언급되는 알려진 거리를 포함하며 두번째는 나머지 거리를 포함한다.
이러한 작업은 지오코딩의 정밀도와 리콜을 향상시키지는 못하지만 이 분할을 사용하여 위치 단계뿐만 아니라 식별 성취도가 증가했다.
- Standardization
- 지명 목록 사전을 소문자로 변경하고, 악센트 부호를 제거한다.
- 약어를 완전한 문장으로 변환한다.
- 빈 간격과 기본값이 있는 경로를 제거한다.
- 별칭의 용어집, 해시태그 단어를 정부가 지정한 이름으로 대체한다.
- 잘못된 위치 주제는 이 작업에서 다루지 않는다.
- 불용어 제거를 위해 Natural Language Toolkit Library를 사용했다.
- Identification and Location of Traffic-Related Events
모든 지리요소 용어사전만을 이용하여 지리요소 식별을 수행하였다.
표지판, 문의, 안전에 대한 게시물이 아무리 많아도 지리 정보가 부족하고 게시된 트윗의 길이가 짧기 때문에 쉽게 제외된다.
또한 트윗은 종종 하나, 둘, 셋 또는 n개의 지리 공간 객체가 고려된다.
이를 표현하기 위해 기본적인 지리적 묘사를 사용하며 조합식을 통해 계산한다.
하지만 지리공간의 연결이 많을수록 정확한 위치 판별이 어렵기 때문에 제한되는 연결만 분석한다.
- (pt): 도시 교통 또는 서비스 스테이션에서 발생하는 이벤트
- (pt, l): 도시 교통 서비스 스테이션 앞의 주요 도로 구간 제한
- (l, l): 주요 도로 교차점에서 발생하는 이벤트
- (pt, pt, l): 두 개의 도시 교통 서비스 스테이션으로 제한된 주요 도로 구간
- (pt, l, l): 다른 주요 도로와 도시 교통 서비스 스테이션에 의해 제한된 주요 도로 구간
- (l, l, l): 두 개의 주요 도로로 구획된 주요 도로 구간 제한
- (l, l, p): 주요 도로와 장소, 건물 또는 역사적 기념물에 의해 구획된 주요 도로 구간
이 연결들과 PostGIS함수를 통해 공간을 식별한다.
- Generation of the Prediction Model
지오코딩된 트윗 모음을 교육 데이터 세트 생성에 사용한다.
학습 데이터셋은 n차원(=특징) 벡터인 입력과 실수(위치)인 출력으로 구성된다.
특징은 트윗이 올라온 날짜 및 시간으로 이루어져있다.
교통 관련 이벤트는 예측이 각 구역과 상관 관계가 있는 구역에 따라 분류되었으며 이 방법을 통해 정밀도와 재현율이 상당히 증가했다. 그 이유로는 먼 위치에 속하는 유사한 값을 가진 벡터를 찾을 가능성이 줄어들기 때문이다.
[ Experimental Results]
실험평가 데이터는 2020년 7월 7일 ~ 2020년 12월 22일사이의 트위터에 65,250개의 게시물을 사용했으며 말뭉치의 각 트윗을 수집하는 출처는 공식 기관 및 인증서 통신 서비스와 관련된 신뢰할 수 있는 Twitter 계정이다.

지오코딩 방법의 정확성을 평가하기 위해 수작업으로 지오코딩된 652개의 트윗을 사용하여 테스트 데이터 세트를 구성했으며 다음 4가지로 정확도를 평가하였다.
기준선 : 지명사전만 사용
첫 번째 평가: 기준선 + 소문자만 사용.
두 번째 평가: 기준선 + 전체 표준화.
세 번째 평가: 기준선 + 전체 표준화 + 동등한 축 이름 용어집 사용

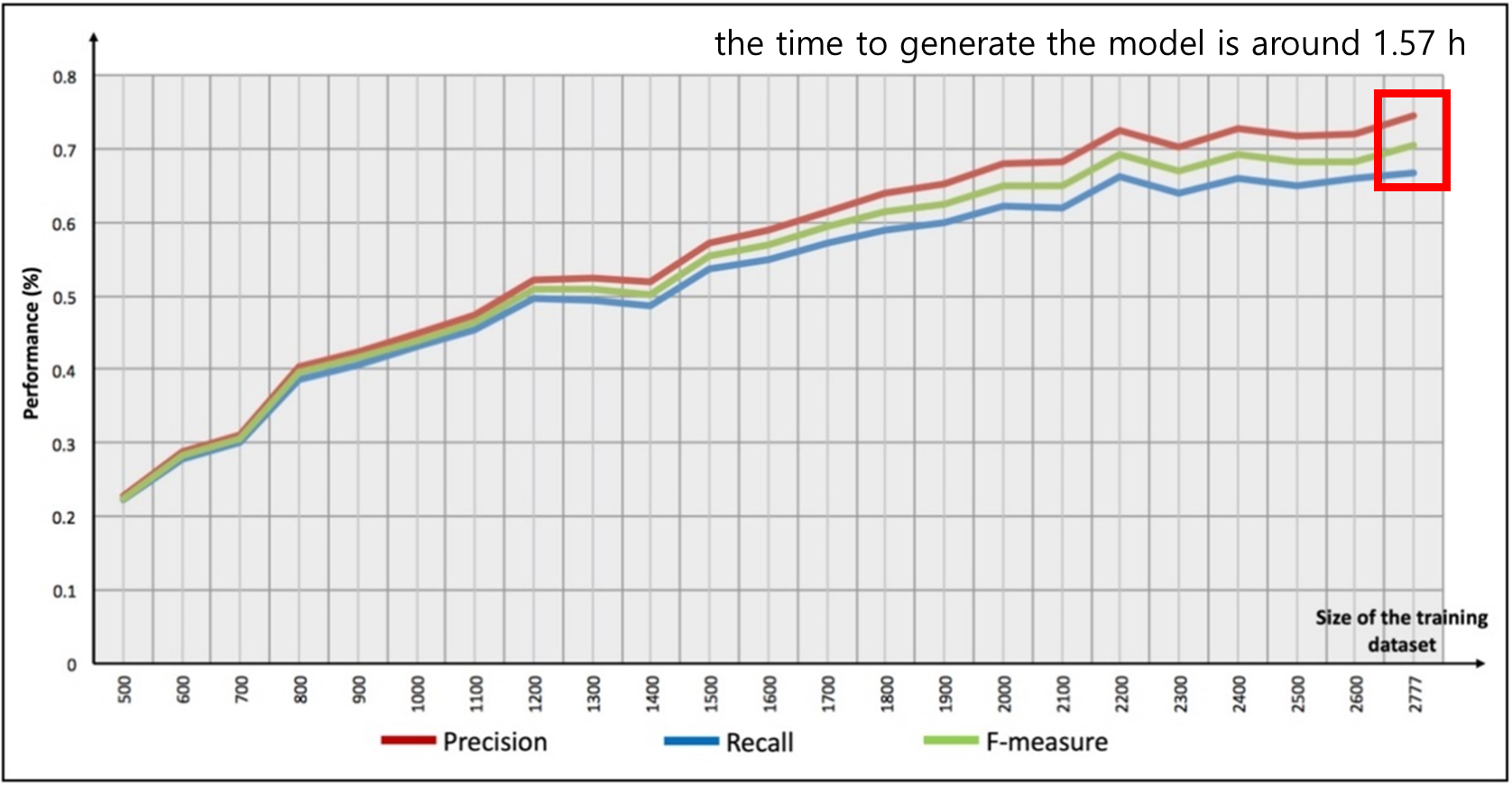
데이터 500개부터 3000개까지 정확도를 분석하였으며 3000개를 학습한 시간은 약 1시간 57분이 소요되었다.
[ Conclusions and Future Works]
주로 정보를 수집하는 저렴한 비용으로 접근 방식을 개발하는 데 중점을 두었으며 인간(= 사용자 생성 콘텐츠)을 센서로 고려한다.
본 논문의 단점으로는 거리의 방향과 관련된 정보를 포함하지 않는 것과 이벤트가 도로에 영향을 미칠 수 있는 기간을 고려하지 않은 것이다. 이는 사고 또는 조건에 대한 합리적인 기간을 설정하기 위해 시간 분석이 필요하다.
향후 연구로는 의료 응용 프로그램의 맥락에서 제공되는 정보를 통합하여 사람들의 스트레스, 포도당 수준 및 파킨슨병 지원 분석을 진행할 예정이다.

