Apache Spark란?
아파치 스파크는 간단하게 스파크라고 많이 불리며, 현재 가장 활발하게 개발되고 있는 병렬 처리 오픈소스 엔진, 통합 컴퓨팅 엔진이며 클러스터 환경에서 데이터를 병렬로 처리하는 라이브러리의 집합이다.
이러한 기능들 덕분에 빅데이터에 관심 있는 여러 개발자와 데이터 과학자에게 표준 도구가 되어가고 있다.
스파크는 파이썬, 자바, 스칼라, R의 총 4가지의 언어를 지원하고 SQL 뿐만 아니라 스트리밍, 머신러닝에 이르기까지 넓은 범위의 라이브러리를 제공한다.
또한 스파크는 단일 노트북 환경에서부터 수천 대의 서버로 구성된 클러스터까지 다양한 환경에서 실행이 가능하다.
이러한 특성을 활용해 빅데이터 처리를 쉽게 할 수 있으며 엄청난 규모의 클러스터로 확장이 가능하다.
아래의 그림은 스파크에서 제공하는 전체 컴포넌트와 라이브러리이므로 참고하길 바란다.
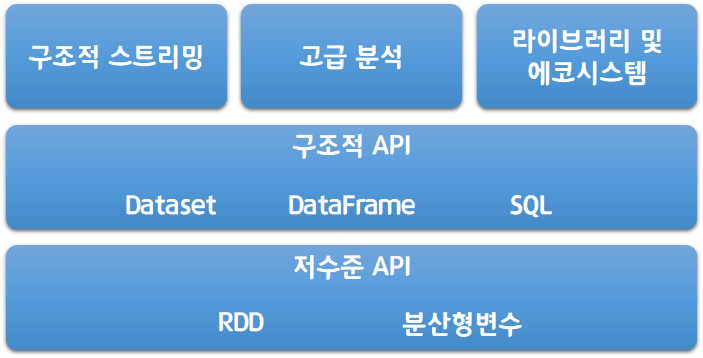
Spark 등장 배경
먼저 아파치 스파크의 등장 배경부터 살펴보자.
그 이유는 스파크 개발 배경인 "사람들은 왜 갑자기 병렬 데이터 처리에 열광하게 되었을까?"의 대한 대답과도 같다.
물론 여러 이유가 있겠지만 데이터 분석에 새로운 처리 엔진과 프로그래밍 모델이 필요한 근본적인 이유는 컴퓨터 애플리케이션과 하드웨어의 바탕을 이루는 경제적 요인의 변화 때문이다.
아래 그래프를 참고하여 보면 이해가 쉬울 것이다.
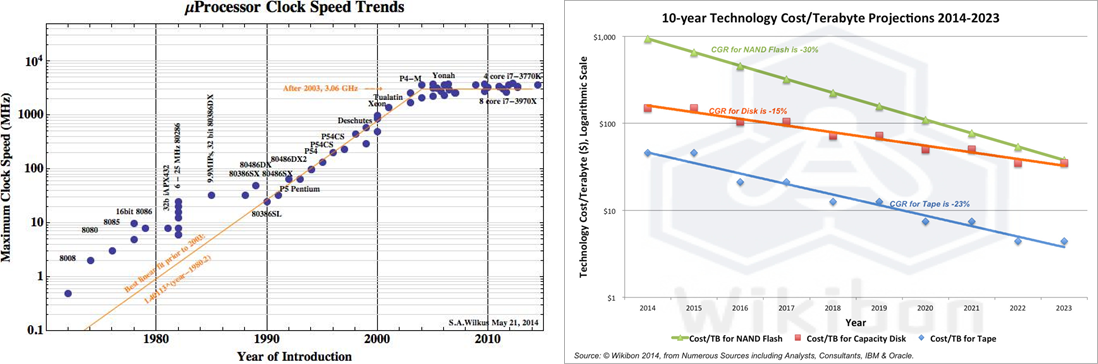
왼쪽의 그래프는 단일 프로세서의 성능이 급격하게 상승하다 2005년경에 성능 향상이 멈추는 것을 보여주는 그래프다. 이는 멀티 코어 프로세서가 탄생하는 계기가 되었으며 이로 인해 병렬 처리의 필요성이 발생하였다.
또한 오른쪽의 그림은 하드웨어의 가격이 저렴해지는 것을 나타내는 그래프이며 이는 데이터의 저장 비용이 저렴해지면서 데이터가 대용량화 됨을 뜻한다. 즉, 클러스터에서 처리해야 할 만큼 방대해짐을 말한다.
이와 같은 이유로 새로운 프로그래밍 모델이 필요해졌으며 이런 문제를 해결하기 위해 아파치 스파크가 탄생하게 되었다.
Spark 철학
아파치 스파크를 '빅데이터를 위한 통합 컴퓨팅 엔진과 라이브러리 집합'이라는 문장으로 설명하였는데, 이 안에 스파크의 3가지 철학(통합, 컴퓨팅 엔진, 라이브러리)이 담겨 있다. 그 의미를 하나씩 살펴보자.
1. 통합
스파크는 '빅데이터 애플리케이션 개발에 필요한 통합 플랫폼을 제공하자'는 핵심 목표를 가지고 있다.
여기서 통합이란 간단한 데이터 읽기부터 SQL 처리, 머신러닝, 스트림 처리까지 다양한 데이터 분석 작업을 같은 연산 엔진과 일관성 있는 API로 수행할 수 있도록 설계하는 것을 말한다.
2. 컴퓨팅 엔진
스파크는 통합이라는 관점을 중시하면서 기능의 범위를 컴퓨팅 엔진으로 제한하면서 데이터 연산 기능만 수행할 뿐 저장소 역할은 수행하지 않는다.
그 대신 클라우드 기반의 저장소(ex : Azure, S3, Hadoop 등)와의 연결을 지원한다.
3. 라이브러리
스파크는 엔진에서 제공하는 표준 라이브러리와 오픈소스 커뮤니티에서 서드파티 패키지 형태로 제공하는 다양한 외부 라이브러리를 지원한다.
스파크 코어 엔진 자체는 최초 공개 후 큰 변화가 없었지만 라이브러리의 경우 더 많은 기능을 제공하기 위해 꾸분히 변해왔다.
그 결과 SQL과 구조화된 데이터를 제공하는 스파크 SQL, 머신러닝을 지원하는 MLib, 그리고 그래프 분석 엔진인 GraphX 등의 라이브러리가 등장했으며 기본 라이브러리 외에 다양한 저장소 시스템을 위한 커넥터와 머신러닝을 위한 알고리즘까지 수백 개의 외부 오픈소스 라이브러리도 존재한다.
외부 라이브러리 목록은 https://spark-packages.org/에서 서 확인할 수 있으니 참고하길 바란다.
Spark 설치하기
스파크를 직접 실행하면서 공부하기 전에 실행에 필요한 준비 사항이 있다.
스파크는 스칼라로 구현되어 자바 가상 머신 기반으로 동작하기 때문에 자바가 설치되어 있어야 하며, 파이썬 API를 사용하려면 파이썬 인터프리터 2.7 버전 이상을, R을 사용하려면 R 언어를 설치해야 한다.
위의 준비가 다 되었다면 다음 과정을 따라 설치를 진행해보자.
1. 스파크 공식 홈페이지 접속
Apache Spark™ - Unified Analytics Engine for Big Data
Ease of Use Write applications quickly in Java, Scala, Python, R, and SQL. Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
spark.apache.org
2. 홈페이지 메뉴 중 Download 클릭
3. 원하는 버전과 패키지 타입 선택 (예시는 하둡 라이브러리를 포함하여 설치)
4. 이동한 페이지 중 아무 곳이나 클릭하여 압축 파일을 다운로드
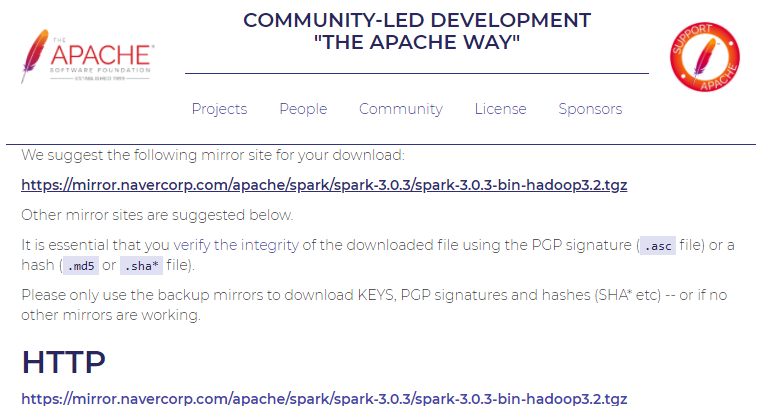
5. 실행하고 싶은 파일로 압출 파일을 옮긴 후 압축을 해제한다.
6. (하둡을 같이 다운로드 한 분들만 하세요!) 아래 url에 접속하여 Spark 다운로드 시 선택한 하둡 버전에 맞는 winutils.exe 파일을 다운로드 받는다.
https://github.com/cdarlint/winutils
cdarlint/winutils
winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - cdarlint/winutils
github.com
맞는 파일을 전체 다운로드하여 같은 버전의 bin 파일만 따로 압축을 해제한다.
후에 압축파일을 저장한 파일과 같은 경로에 hadoop파일을 만들고 그 안에 bin 파일 생성하여 저장한다.
예를 들어, C://Spark/압축파일이라면 C://Hadoop/bin/winutils.exe로 저장한다.
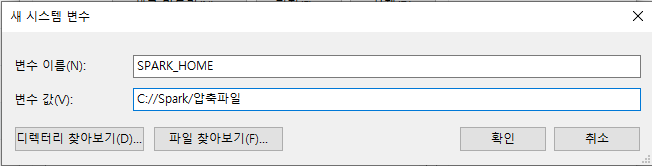
7. 환경 변수 설정
시스템 속성의 환경 변수로 들어가 새로 만들기를 클릭한다.
그리고 다음 그림과 같이 입력해준다.
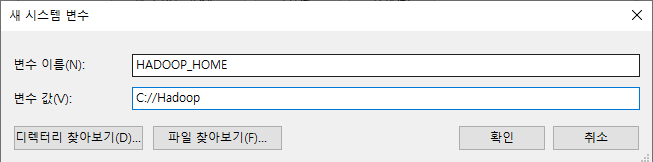
하둡을 설치하였으면 위와 같이 새로 만들기를 한번 더 실행한다.
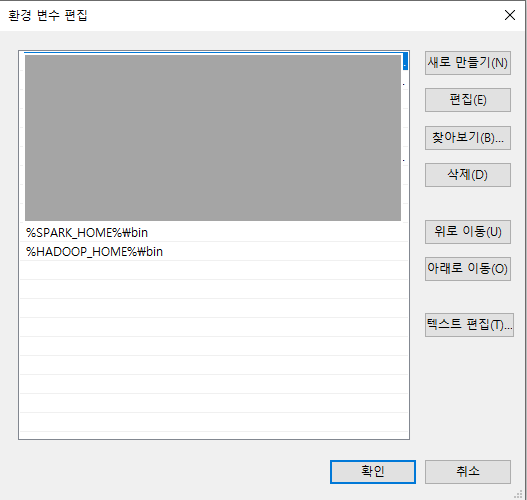
다음으로 시스템 변수 중 Path를 클릭하여 %SPARK_HOME%\bin과 %HADOOP_HOME%\bin 을 추가한다.
Spark 실행하기
▶ 스파크 대화형 콘솔 실행
1. 스칼라 콘솔 실행
스파크 홈 디렉터리에서 ./bin/spark-shell 실행
2. 파이썬 콘솔 실행
스파크 홈 디렉터리에서 ./bin/pyspark 실행
▶ SQL 콘솔 실행
스파크 홈 디렉터리에서 ./bin/spark-sql실행

이 부분에서 꽤나 애먹었는데, 위에서 다운로드 받았던 winutils.exe 파일에 모든 권한을 주지 않으면 실행이 되지 않는 경우가 생긴다(ㅜㅜ....)
내가 본 에러의 종류는 여러 가지인데 다 날라갔.... 쨋든! 해당되시면 밑의 코드로 해결하시길...
1. WARN NativeIO: NativeIO.getStat error (3): 지정된 경로를 찾을 수 없습니다.
2. winutils.exe 파일 언급하면서 경로 어쩌고 저쩌고 함..
등등... 일단 실행이 안됨 ㅠㅠㅠㅠㅠㅠㅠ
그럴 경우에 명령 프롬프트 창에서 다음과 같이 입력해주자!
"1.winutils.exe 파일이 있는 전체 경로 입력" chmod 777 2.tmp/hive파일이 있는 경로 입력
1번의 경우 아까 설치했던 파일이 있는 경로를 하드 경로로 입력해주면 된다.
예를 들어, C:\Hadoop\bin\winutils.exe처럼 입력해주면 된다.
2번의 경우 미리 hive 파일이 있는 경우를 찾아 주자.
나의 경우 D 드라이브에 존재해서 D:\tmp\hive라고 입력했다.
그랬더니 바로 실행이 되더라 ㅎㅎ(휴... 끈질겼다.,..)
무튼 실행까지 잘 되었으니! 오늘은 여기까지!!
'SEMINAR > 스파크 완벽 가이드' 카테고리의 다른 글
| 2-1. Spark의 저수준 API (0) | 2021.07.23 |
|---|---|
| 1-2. 스파크 간단히 살펴보기 (0) | 2021.07.10 |

