텍스트 분류란 자연어 처리 기술을 활용해 글의 정보를 추출해서 문제에 맞게 사람이 정한 범주(Class)로 분류하는 문제다.
텍스트 분류의 방법과 예시 등 이론적인 내용은 앞에서 살펴봤으므로 참고하면 좋겠다.
Chap03. 자연어처리 개요_텍스트 분류 및 유사도
오늘은 자연어 처리 문제 중 가장 대표적이고 많이 하는 텍스트 분류와 텍스트끼리 얼마나 비슷한지를 계산하는 유사도에 대하여 알아보도록 하자. [ 텍스트 분류 ] 텍스트 분류(Text Classification)
yuna96.tistory.com
이번 포스팅에서는 실제로 데이터를 가지고 텍스트 분류를 실습하면서 텍스트 분류가 무엇인지에 대해 알아보도록 하자.
실습은 영어와 한글을 나누어서 진행하는데, 그 이유는 자연어 처리 기술을 통해 언어를 처리하는 과정이 각 언어의 특성에 따라 다르기 때문이다.
텍스트 분류 중 감정 분류에 대해서 실습을 진행해보자.
01. 영어 텍스트 분류

▶ 데이터 분석 및 전처리
분석할 데이터를 불러오고 분석하는 과정을 거친 후에 전처리 과정을 진행한다.
분석은 이전에 알아본 탐색적 데이터 분석(EDA) 과정으로, 전처리 전에 데이터에 대해 알아보는 과정이다.
전처리는 데이터를 모델에 적용하기에 적합하도록 데이터를 정제하는 과정이다.
이 과정을 정리하면 다음과 같다.
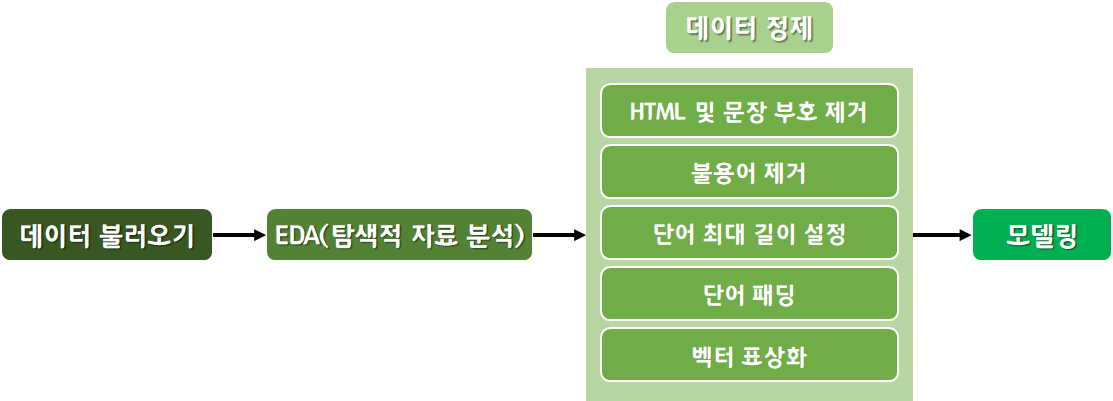
º 데이터 불러오기 및 분석
데이터를 불러오는 방법은 두 가지가 있다.
첫 번째는, 캐글 홈페이지에 들어가서 "Bag of Word meets bag of popcorn" 문제를 직접 다운로드한다.
해당 페이지에서 데이터 탭의 다운로드 메뉴를 통해 내려받으면 된다.
두 번째는 캐글 API를 사용해 내려받는다.
API를 사용하는 경우 명령행에 다음 명령어를 입력해서 받는다.
kaggle competitions download -c word2vec-nlp-tutorial위의 명령을 입력하면 4개의 파일이 다운로드된다.
- sampleSubmission.csv
- unlabeledTrainData.tsv.zip
- testData.tsv.zip
- labeledTrainData.tsv.zip
이제 데이터를 불러온 후 데이터를 분석해보자.
우선 sampleSubmission.csv 파일을 제외한 나머지 파일이 압축되어 있으므로 압축을 푸는 과정부터 시작한다.
압축을 풀기 위해 zipfile이라는 기본 내장 라이브러리를 불러오자.
import zipfile다음으로 압축을 풀기 위해 경로와 압축을 풀 파일명을 리스트로 선언해 반복문을 통해 압축을 풀어준다.
DATA_IN_PATH = './data_in/'
file_list = ['labeledTrainData.tsv.zip', 'unlabeledTrainData.tsv.zip', 'testData.tsv.zip']
for file in file_list:
zipRef = zipfile.ZipFile(DATA_IN_PATH + file, 'r')
zipRef.extractall(DATA_IN_PATH)
zipRef.close()경로를 따라가 보면 압축 해제가 잘 된 것을 확인할 수 있다.
이제 데이터를 불러와서 분석할 준비가 끝났으므로 분석을 실행해보자.
분석 순서는 다음과 같다.
- 데이터 크기
- 데이터의 개수
- 각 리뷰의 문자 길이 분포
- 많이 사용된 단어
- 긍, 부정 데이터의 분포
- 각 리뷰의 단어 개수 분포
- 특수문자 및 대, 소문자 비율
우선 분석에 필요한 라이브러리를 불러온다.
import numpy as np # 넘파이
import pandas as pd # 판다스
import os # (기본 내장 라이브러리) os
import matplotlib.pyplot as plt # 맷플롯립
import seaborn as sns # 씨본
%matplotlib inline #(주피터 사용시)불러온 데이터의 구조를 살펴보기 위해 head함수를 사용해서 샘플 데이터 5개만 확인해보자.
train_data = pd.read_csv( DATA_IN_PATH + 'labeledTrainData.tsv', header = 0, delimiter = '\t', quoting = 3)
train_data.head()결과 :

데이터는 id, sentiment, review로 구분되어 있으며 sentiment는 레이블을 나타내고 review는 텍스트를 나타낸다.
다음 데이터를 사용해서 위에서 말한 순서대로 분석을 진행해보자.
1. 데이터 크기
데이터 크기는 다음의 코드를 통해 확인할 수 있다.
print("파일 크기 : ")
for file in os.listdir(DATA_IN_PATH):
if 'tsv' in file and 'zip' not in file:
print(file.ljust(30) + str(round(os.path.getsize(DATA_IN_PATH + file) / 1000000, 2)) + 'MB')결과 :
파일 크기 :
labeledTrainData.tsv 33.56MB
testData.tsv 32.72MB
unlabeledTrainData.tsv 67.28MB
코드 설명은 다음과 같다.
1) os 라이브러리를 사용해 해당 경로의 파일 목록을 가져온다.
2) 해당 폴더에는 압축 파일과 압축이 풀린 파일이 같이 있으므로 압축 파일을 제외한 파일들을 가져온다.
3) 가져온 파일들의 크기를 출력한다.
다음 코드를 실행한 결과를 보면 unlabeledTrainData.tsv파일이 가장 크고 나머지 두 개는 비슷한 것을 알 수 있다.
이는 레이블이 있는 학습 데이터와 테스트에 사용될 평가 데이터의 크기가 비슷함을 알 수 있으며, 레이블이 없는 학습 데이터의 크기가 가장 큰 것을 알 수 있다.
2. 데이터 개수
데이터 개수를 확인하는 코드는 다음과 같다.
print('전체 학습데이터의 개수: {}'.format(len(train_data)))결과 :
전체 학습 데이터의 개수: 25000
학습 데이터의 개수는 2만 5천 개라는 사실을 알 수 있다.
3. 각 리뷰의 문자 길이 분포
각 문자 길이를 확인하는 코드는 다음과 같다.
train_length = train_data['review'].apply(len)
train_length.head()결과 :
0 2304
1 948
2 2451
3 2247
4 2233
Name: review, dtype: int64
먼저 각 리뷰의 길이를 새로운 변수로 정의하고 head 함수를 사용해 샘플 데이터 몇 개만 확인해본 결과, 해당 변수에는 각 리뷰의 길이가 담겨 있는 것을 확인하였다.
이 변수를 사용해 히스토그램을 그려보자.
# 그래프에 대한 이미지 사이즈 선언
# figsize: (가로, 세로) 형태의 튜플로 입력
plt.figure(figsize=(12, 5))
# 히스토그램 선언
# bins: 히스토그램 값들에 대한 버켓 범위
# range: x축 값의 범위
# alpha: 그래프 색상 투명도
# color: 그래프 색상
# label: 그래프에 대한 라벨
plt.hist(train_length, bins=200, alpha=0.5, color= 'r', label='word')
plt.yscale('log', nonposy='clip')
# 그래프 제목
plt.title('Log-Histogram of length of review')
# 그래프 x 축 라벨
plt.xlabel('Length of review')
# 그래프 y 축 라벨
plt.ylabel('Number of review')결과 :

분포를 보면 각 리뷰의 문자 길이가 대부분 6000 이하인 것을 알 수 있으며, 평균적으로 2000 이하가 많은 것을 알 수 있다. 또한 이상치로 10000 이상의 값을 가지는 것을 한눈에 알 수 있다.
길이에 대한 통계 값은 다음과 같이 구할 수 있다.
print('리뷰 길이 최대 값: {}'.format(np.max(train_length)))
print('리뷰 길이 최소 값: {}'.format(np.min(train_length)))
print('리뷰 길이 평균 값: {:.2f}'.format(np.mean(train_length)))
print('리뷰 길이 표준편차: {:.2f}'.format(np.std(train_length)))
print('리뷰 길이 중간 값: {}'.format(np.median(train_length)))
# 사분위의 대한 경우는 0~100 스케일로 되어있음
print('리뷰 길이 제 1 사분위: {}'.format(np.percentile(train_length, 25)))
print('리뷰 길이 제 3 사분위: {}'.format(np.percentile(train_length, 75)))결과 :
리뷰 길이 최대 값: 13710
리뷰 길이 최소 값: 54
리뷰 길이 평균값: 1329.71
리뷰 길이 표준편차: 1005.22
리뷰 길이 중간 값: 983.0
리뷰 길이 제1 사분위: 705.0
리뷰 길이 제3 사분위: 1619.0
리뷰의 길이가 히스토그램과 비슷하게 평균이 1300 정도이며, 최댓값이 13000이라는 것을 알 수 있다.
다음 데이터를 통해 박스 플롯을 그려보자.
plt.figure(figsize=(12, 5))
# 박스플롯 생성
# 첫번째 파라메터: 여러 분포에 대한 데이터 리스트를 입력
# labels: 입력한 데이터에 대한 라벨
# showmeans: 평균값을 마크함
plt.boxplot(train_length,
labels=['counts'],
showmeans=True)결과 :

박스 플롯 그래프를 보면 데이터의 길이가 대부분 2000 이하로 평균이 1500 이하이며, 길이가 4000 이상인 이상치 데이터도 많이 분포되어 있는 것을 확인할 수 있다.
4. 많이 사용된 단어
많이 사용된 단어를 알기 위해 wordcloud를 사용한다.
from wordcloud import WordCloud
cloud = WordCloud(width=800, height=600).generate(" ".join(train_data['review']))
plt.figure(figsize=(20, 15))
plt.imshow(cloud)
plt.axis('off')결과 :
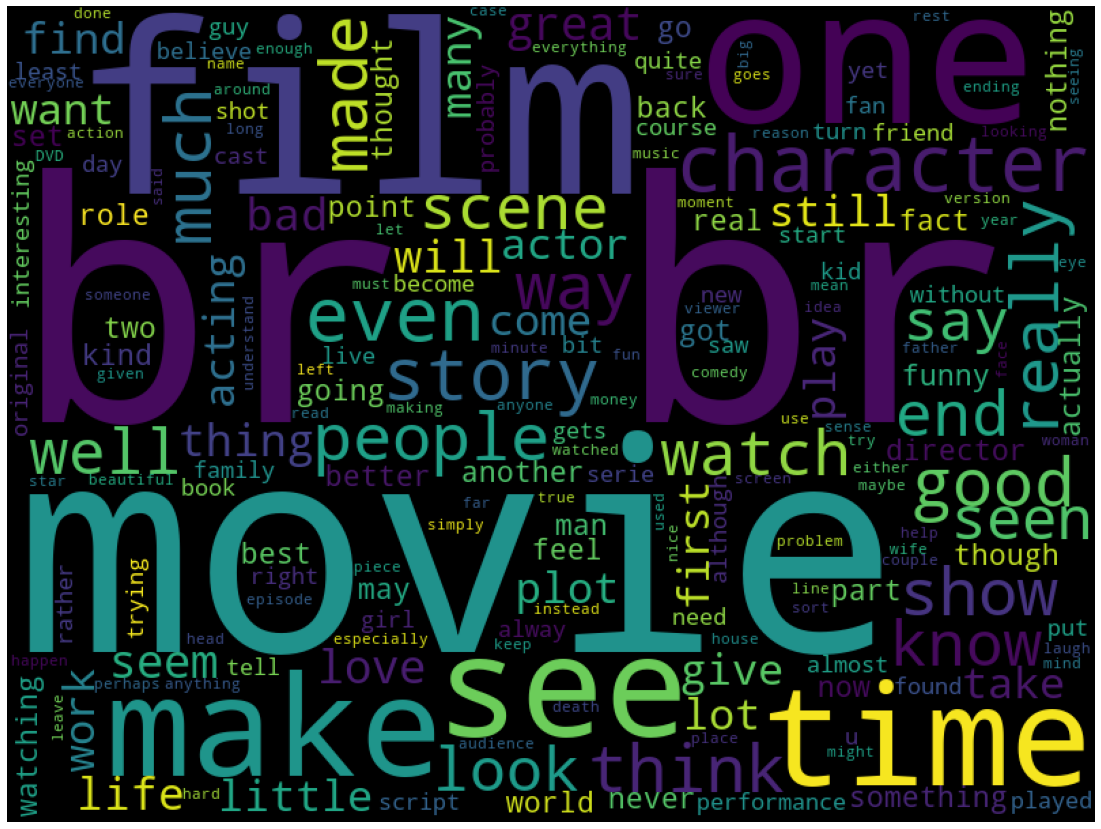
결과를 보면 br이 가장 많이 사용된 것을 알 수 있으며 이는 html 태그 중 하나이기 때문에 정제 작업이 필요한 것을 알 수 있다.
5. 긍/부정의 데이터 분포
해당 데이터의 경우 긍정과 부정이라는 두 가지 레이블을 가지고 있기 때문에 씨본을 사용해 시각화해보자.
fig, axe = plt.subplots(ncols=1)
fig.set_size_inches(6, 3)
sns.countplot(train_data['sentiment'])결과 :

레이블 분포 그래프를 보면 거의 동일한 개수로 분포돼 있음을 확인할 수 있다.
각 레이블에 대해 정확한 값을 확인해보자.
print("긍정 리뷰 개수: {}".format(train_data['sentiment'].value_counts()[1]))
print("부정 리뷰 개수: {}".format(train_data['sentiment'].value_counts()[0]))결과 :
긍정 리뷰 개수: 12500
부정 리뷰 개수: 12500
결과를 보면 정확하게 같은 값을 가진다는 것을 확인할 수 있다.
6. 각 리뷰의 단어 개수 분포
단어는 띄어쓰기 기준으로 하나의 단어라고 생각하고 계산을 진행한다.
먼저, 각 단어의 길이를 가지는 변수를 하나 설정한다.
train_word_counts = train_data['review'].apply(lambda x:len(x.split(' ')))이 변수의 값으로 위와 동일하게 히스토그램으로 확인하자.
plt.figure(figsize=(15, 10))
plt.hist(train_word_counts, bins=50, facecolor='r',label='train')
plt.title('Log-Histogram of word count in review', fontsize=15)
plt.yscale('log', nonposy='clip')
plt.legend()
plt.xlabel('Number of words', fontsize=15)
plt.ylabel('Number of reviews', fontsize=15)결과 :
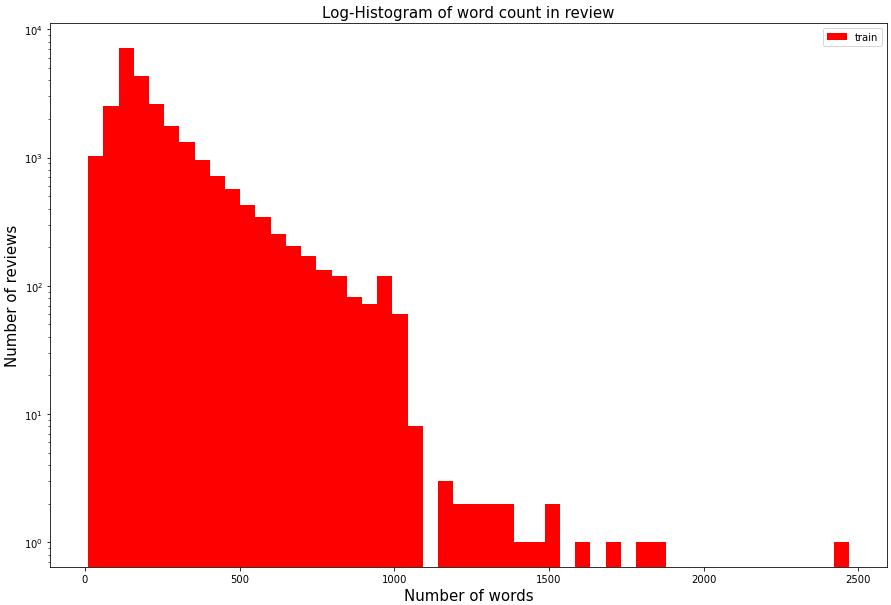
대부분의 리뷰가 1000개 미만의 단어를 가지고 있고, 대부분 200개 정도의 단어를 가지고 있음을 확인할 수 있다.
마지막으로 통계 값을 통해 확인해보자.
print('리뷰 단어 개수 최대 값: {}'.format(np.max(train_word_counts)))
print('리뷰 단어 개수 최소 값: {}'.format(np.min(train_word_counts)))
print('리뷰 단어 개수 평균 값: {:.2f}'.format(np.mean(train_word_counts)))
print('리뷰 단어 개수 표준편차: {:.2f}'.format(np.std(train_word_counts)))
print('리뷰 단어 개수 중간 값: {}'.format(np.median(train_word_counts)))
# 사분위의 대한 경우는 0~100 스케일로 되어있음
print('리뷰 단어 개수 제 1 사분위: {}'.format(np.percentile(train_word_counts, 25)))
print('리뷰 단어 개수 제 3 사분위: {}'.format(np.percentile(train_word_counts, 75)))결과 :
리뷰 단어 개수 최대 값: 2470
리뷰 단어 개수 최소 값: 10
리뷰 단어 개수 평균값: 233.79
리뷰 단어 개수 표준편차: 173.74
리뷰 단어 개수 중간 값: 174.0
리뷰 단어 개수 제1 사분위: 127.0
리뷰 단어 개수 제3 사분위: 284.0
결과를 보면 평균이 233개이고, 최댓값의 경우 2470개의 단어를 가지고 있다.
그리고 3 사분위 값을 보면 284개로 리뷰의 75%가 300개 이하의 단어를 가지고 있음을 확인할 수 있다.
7. 특수문자 및 대, 소문자 비율
qmarks = np.mean(train_data['review'].apply(lambda x: '?' in x)) # 물음표가 구두점으로 쓰임
fullstop = np.mean(train_data['review'].apply(lambda x: '.' in x)) # 마침표
capital_first = np.mean(train_data['review'].apply(lambda x: x[0].isupper())) # 첫번째 대문자
capitals = np.mean(train_data['review'].apply(lambda x: max([y.isupper() for y in x]))) # 대문자가 몇개
numbers = np.mean(train_data['review'].apply(lambda x: max([y.isdigit() for y in x]))) # 숫자가 몇개
print('물음표가있는 질문: {:.2f}%'.format(qmarks * 100))
print('마침표가 있는 질문: {:.2f}%'.format(fullstop * 100))
print('첫 글자가 대문자 인 질문: {:.2f}%'.format(capital_first * 100))
print('대문자가있는 질문: {:.2f}%'.format(capitals * 100))
print('숫자가있는 질문: {:.2f}%'.format(numbers * 100))결과 :
물음표가 있는 질문: 29.55%
마침표가 있는 질문: 99.69%
첫 글자가 대문자 인 질문: 0.00%
대문자가 있는 질문: 99.59%
숫자가 있는 질문: 56.66%
결과를 보면 대부분 마침표를 포함하고 있으며, 대문자 또한 대부분 사용하고 있다.
따라서 전처리 과정에서 대문자를 모두 소문자로 바꾸고 특수문자의 경우 제거 작업을 해준다.
(학습에 방해되는 요소들을 제거하기 위해서이다!)
º 데이터 전처리
이제 데이터를 모델에 적용할 수 있도록 데이터 전처리를 해보자.
먼저 전처리 과정에서 사용할 라이브러리들을 불러온다.
import re # 정규표현식
import json
import pandas as pd # 판다스
import numpy as np
from bs4 import BeautifulSoup
from nltk.corpus import stopwords
from tensorflow.python.keras.preprocessing.sequence import pad_sequences # 텐서플로
from tensorflow.python.keras.preprocessing.text import Tokenizer # 텐서플로데이터를 분석하기에 앞서 학습 데이터를 불러온 후 첫 번째 리뷰를 출력해보자.
DATA_IN_PATH = './data_in/'
train_data = pd.read_csv( DATA_IN_PATH + 'labeledTrainData.tsv', header = 0, delimiter = '\t', quoting = 3)
print(train_data['review'][0])결과 :
"With all this stuff going down at the moment with MJ i've started listening to his music, watching the odd documentary here and there, watched The Wiz and watched Moonwalker again. Maybe i just want to get a certain insight into this guy who i thought was really cool in the eighties just to maybe make up my mind whether he is guilty or innocent. Moonwalker is part biography, part feature film which i remember going to see at the cinema when it was originally released. Some of it has subtle messages about MJ's feeling towards the press and also the obvious message of drugs are bad m'kay.<br /><br />Visually impressive but of course this is all about Michael Jackson so unless you remotely like MJ in anyway then you are going to hate this and find it boring. Some may call MJ an egotist for consenting to the making of this movie BUT MJ and most of his fans would say that he made it for the fans which if true is really nice of him.<br /><br />The actual feature film bit when it finally starts is only on for 20 minutes or so excluding the Smooth Criminal sequence and Joe Pesci is convincing as a psychopathic all powerful drug lord. Why he wants MJ dead so bad is beyond me. Because MJ overheard his plans? Nah, Joe Pesci's character ranted that he wanted people to know it is he who is supplying drugs etc so i dunno, maybe he just hates MJ's music.<br /><br />Lots of cool things in this like MJ turning into a car and a robot and the whole Speed Demon sequence. Also, the director must have had the patience of a saint when it came to filming the kiddy Bad sequence as usually directors hate working with one kid let alone a whole bunch of them performing a complex dance scene.<br /><br />Bottom line, this movie is for people who like MJ on one level or another (which i think is most people). If not, then stay away. It does try and give off a wholesome message and ironically MJ's bestest buddy in this movie is a girl! Michael Jackson is truly one of the most talented people ever to grace this planet but is he guilty? Well, with all the attention i've gave this subject....hmmm well i don't know because people can be different behind closed doors, i know this for a fact. He is either an extremely nice but stupid guy or one of the most sickest liars. I hope he is not the latter."
데이터를 확인해보면 <br />과 같은 HTML 태그와 '...'같은 특수문자가 포함된 것을 볼 수 있다.
이런 문장부호 및 특수문자는 문장 의미에 영향을 크게 미치지 않기 때문에 최적화된 학습을 위해 제거하는 단계를 거쳐야 한다.
review = train_data['review'][0] # 리뷰 중 하나를 가져온다.
review_text = BeautifulSoup(review,"html5lib").get_text() # HTML 태그 제거
review_text = re.sub("[^a-zA-Z]", " ", review_text ) # 영어 문자를 제외한 나머지는 모두 공백으로 바꾼다.Beautiful Soup 라이브러리를 사용하여 HTML 태그를 제거하고, re 라이브러리를 통해 영어 알파벳을 제외한 모든 문자를 공백으로 대체한다.
이러한 과정을 거친 데이터는 다음과 같다.
print(review_text)결과 :
With all this stuff going down at the moment with MJ i ve started listening to his music watching the odd documentary here and there watched The Wiz and watched Moonwalker again Maybe i just want to get a certain insight into this guy who i thought was really cool in the eighties just to maybe make up my mind whether he is guilty or innocent Moonwalker is part biography part feature film which i remember going to see at the cinema when it was originally released Some of it has subtle messages about MJ s feeling towards the press and also the obvious message of drugs are bad m kay Visually impressive but of course this is all about Michael Jackson so unless you remotely like MJ in anyway then you are going to hate this and find it boring Some may call MJ an egotist for consenting to the making of this movie BUT MJ and most of his fans would say that he made it for the fans which if true is really nice of him The actual feature film bit when it finally starts is only on for minutes or so excluding the Smooth Criminal sequence and Joe Pesci is convincing as a psychopathic all powerful drug lord Why he wants MJ dead so bad is beyond me Because MJ overheard his plans Nah Joe Pesci s character ranted that he wanted people to know it is he who is supplying drugs etc so i dunno maybe he just hates MJ s music Lots of cool things in this like MJ turning into a car and a robot and the whole Speed Demon sequence Also the director must have had the patience of a saint when it came to filming the kiddy Bad sequence as usually directors hate working with one kid let alone a whole bunch of them performing a complex dance scene Bottom line this movie is for people who like MJ on one level or another which i think is most people If not then stay away It does try and give off a wholesome message and ironically MJ s bestest buddy in this movie is a girl Michael Jackson is truly one of the most talented people ever to grace this planet but is he guilty Well with all the attention i ve gave this subject hmmm well i don t know because people can be different behind closed doors i know this for a fact He is either an extremely nice but stupid guy or one of the most sickest liars I hope he is not the latter
다음으로 불용어를 제거해보자.
불용어란, 문장에서 자주 출현하나 전체적인 의미에 큰 영향을 주지 않는 단어를 말한다.
예로 조사, 관사 등을 말할 수 있다.
데이터에 따라 불용어를 제거하는 것은 장단점이 존재하는데, 경우에 따라서는 불용어가 포함된 데이터를 모델링하는 데 있어 노이즈를 줄 수 있는 요인이 될 수 있어 불용어를 제거하는 것이 좋다.
하지만 데이터가 많고 문장 구문에 대한 전체적인 패턴을 모델링하고자 한다면 역효과를 줄 수도 있다.
그러므로 불용어를 제거하는 것이 꼭 좋은 것은 아니며 분석하고자 하는 것에 따라 사용자가 지정해주면 된다.
이번 포스팅에서의 감정 분석은 불용어가 감정 판단에 영향을 주지 않는다고 가정하고 불용어를 제거한다.
불용어를 제거하려면 따로 정의한 불용어 사전을 이용해야 한다.
사용자가 직접 정의할 수도 있지만 불용어가 너무 많기 때문에 보통 라이브러리에서 지정한 불용어 사전을 이용한다.
그전에 NLTK에서 제공하는 불용어 사전은 전부 소문자 단어로 되어있어 불용어를 제거하기 위해서는 모든 단어를 소문자로 바꾼 후 제거해야 한다.
stop_words = set(stopwords.words('english')) # 영어 불용어들의 set을 만든다.
review_text = review_text.lower()
words = review_text.split() # 소문자 변환 후 단어마다 나눠서 단어 리스트로 만든다.
words = [w for w in words if not w in stop_words] # 불용어 제거한 리스트를 만든다
print(words)결과 :
['stuff', 'going', 'moment', 'mj', 'started', 'listening', 'music', 'watching', 'odd', 'documentary', 'watched', 'wiz', 'watched', 'moonwalker', 'maybe', 'want', 'get', 'certain', 'insight', 'guy', 'thought', 'really', 'cool', 'eighties', 'maybe', 'make', 'mind', 'whether', 'guilty', 'innocent', 'moonwalker', 'part', 'biography', 'part', 'feature', 'film', 'remember', 'going', 'see', 'cinema', 'originally', 'released', 'subtle', 'messages', 'mj', 'feeling', 'towards', 'press', 'also', 'obvious', 'message', 'drugs', 'bad', 'kay', 'visually', 'impressive', 'course', 'michael', 'jackson', 'unless', 'remotely', 'like', 'mj', 'anyway', 'going', 'hate', 'find', 'boring', 'may', 'call', 'mj', 'egotist', 'consenting', 'making', 'movie', 'mj', 'fans', 'would', 'say', 'made', 'fans', 'true', 'really', 'nice', 'actual', 'feature', 'film', 'bit', 'finally', 'starts', 'minutes', 'excluding', 'smooth', 'criminal', 'sequence', 'joe', 'pesci', 'convincing', 'psychopathic', 'powerful', 'drug', 'lord', 'wants', 'mj', 'dead', 'bad', 'beyond', 'mj', 'overheard', 'plans', 'nah', 'joe', 'pesci', 'character', 'ranted', 'wanted', 'people', 'know', 'supplying', 'drugs', 'etc', 'dunno', 'maybe', 'hates', 'mj', 'music', 'lots', 'cool', 'things', 'like', 'mj', 'turning', 'car', 'robot', 'whole', 'speed', 'demon', 'sequence', 'also', 'director', 'must', 'patience', 'saint', 'came', 'filming', 'kiddy', 'bad', 'sequence', 'usually', 'directors', 'hate', 'working', 'one', 'kid', 'let', 'alone', 'whole', 'bunch', 'performing', 'complex', 'dance', 'scene', 'bottom', 'line', 'movie', 'people', 'like', 'mj', 'one', 'level', 'another', 'think', 'people', 'stay', 'away', 'try', 'give', 'wholesome', 'message', 'ironically', 'mj', 'bestest', 'buddy', 'movie', 'girl', 'michael', 'jackson', 'truly', 'one', 'talented', 'people', 'ever', 'grace', 'planet', 'guilty', 'well', 'attention', 'gave', 'subject', 'hmmm', 'well', 'know', 'people', 'different', 'behind', 'closed', 'doors', 'know', 'fact', 'either', 'extremely', 'nice', 'stupid', 'guy', 'one', 'sickest', 'liars', 'hope', 'latter']
먼저 코드부터 보면 lower함수를 사용해 소문자로 바꾼 후, split함수로 띄어쓰기를 기준으로 단어 리스트를 생성한다.
다음으로 리스트에서 불용어에 해당하지 않는 단어만 다시 모아서 리스트로 만든다.
중간에 속도 향상을 위해 set타입으로 정의한 후 사용한다.
결과를 보면 하나의 문자열이었던 리뷰가 단어 리스트로 바뀐 것을 확인할 수 있는데, 이를 모델에 적용하기 위해선 다시 문자열로 바꿔줘야 한다.
때문에 문자열로 만들기 위해서 join함수를 사용한다.
clean_review = ' '.join(words) # 단어 리스트들을 다시 하나의 글로 합친다.
print(clean_review)결과 :
stuff going moment mj started listening music watching odd documentary watched wiz watched moonwalker maybe want get certain insight guy thought really cool eighties maybe make mind whether guilty innocent moonwalker part biography part feature film remember going see cinema originally released subtle messages mj feeling towards press also obvious message drugs bad kay visually impressive course michael jackson unless remotely like mj anyway going hate find boring may call mj egotist consenting making movie mj fans would say made fans true really nice actual feature film bit finally starts minutes excluding smooth criminal sequence joe pesci convincing psychopathic powerful drug lord wants mj dead bad beyond mj overheard plans nah joe pesci character ranted wanted people know supplying drugs etc dunno maybe hates mj music lots cool things like mj turning car robot whole speed demon sequence also director must patience saint came filming kiddy bad sequence usually directors hate working one kid let alone whole bunch performing complex dance scene bottom line movie people like mj one level another think people stay away try give wholesome message ironically mj bestest buddy movie girl michael jackson truly one talented people ever grace planet guilty well attention gave subject hmmm well know people different behind closed doors know fact either extremely nice stupid guy one sickest liars hope latter
이러한 전처리 과정을 하나의 함수로 정의하여 모든 데이터에 적용하자.
먼저 전처리에 대한 함수를 다음과 같이 정의한다.
def preprocessing( review, remove_stopwords = False ):
# 불용어 제거는 옵션으로 선택 가능하다.
# 1. HTML 태그 제거
review_text = BeautifulSoup(review, "html5lib").get_text()
# 2. 영어가 아닌 특수문자들을 공백(" ")으로 바꾸기
review_text = re.sub("[^a-zA-Z]", " ", review_text)
# 3. 대문자들을 소문자로 바꾸고 공백단위로 텍스트들 나눠서 리스트로 만든다.
words = review_text.lower().split()
if remove_stopwords:
# 4. 불용어들을 제거
#영어에 관련된 불용어 불러오기
stops = set(stopwords.words("english"))
# 불용어가 아닌 단어들로 이루어진 새로운 리스트 생성
words = [w for w in words if not w in stops]
# 5. 단어 리스트를 공백을 넣어서 하나의 글로 합친다.
clean_review = ' '.join(words)
else: # 불용어 제거하지 않을 때
clean_review = ' '.join(words)
return clean_review
함수의 경우 불용어 제거는 인자 값으로 받아서 선택할 수 있게 되어있다.
이렇게 정의한 함수를 사용해 전체 데이터를 전처리한 후 데이터 하나를 확인해보자.
clean_train_reviews = []
for review in train_data['review']:
clean_train_reviews.append(preprocessing(review, remove_stopwords = True))
# 전처리한 데이터 출력
clean_train_reviews[0]결과 :
'stuff going moment mj started listening music watching odd documentary watched wiz watched moonwalker maybe want get certain insight guy thought really cool eighties maybe make mind whether guilty innocent moonwalker part biography part feature film remember going see cinema originally released subtle messages mj feeling towards press also obvious message drugs bad kay visually impressive course michael jackson unless remotely like mj anyway going hate find boring may call mj egotist consenting making movie mj fans would say made fans true really nice actual feature film bit finally starts minutes excluding smooth criminal sequence joe pesci convincing psychopathic powerful drug lord wants mj dead bad beyond mj overheard plans nah joe pesci character ranted wanted people know supplying drugs etc dunno maybe hates mj music lots cool things like mj turning car robot whole speed demon sequence also director must patience saint came filming kiddy bad sequence usually directors hate working one kid let alone whole bunch performing complex dance scene bottom line movie people like mj one level another think people stay away try give wholesome message ironically mj bestest buddy movie girl michael jackson truly one talented people ever grace planet guilty well attention gave subject hmmm well know people different behind closed doors know fact either extremely nice stupid guy one sickest liars hope latter'
이제 전체 데이터를 데이터 프레임으로 만들어 둔 후 각 데이터 단어들을 벡터화한 후 패딩 과정을 진행해보자.
clean_train_df = pd.DataFrame({'review': clean_train_reviews, 'sentiment': train_data['sentiment']})
tokenizer = Tokenizer()
tokenizer.fit_on_texts(clean_train_reviews)
text_sequences = tokenizer.texts_to_sequences(clean_train_reviews)
print(text_sequences[0])결과 :
[404, 70, 419, 8815, 506, 2456, 115, 54, 873, 516, 178, 18686, 178, 11242, 165, 78, 14, 662, 2457, 117, 92, 10, 499, 4074, 165, 22, 210, 581, 2333, 1194, 11242, 71, 4826, 71, 635, 2, 253, 70, 11, 302, 1663, 486, 1144, 3265, 8815, 411, 793, 3342, 17, 441, 600, 1500, 15, 4424, 1851, 998, 146, 342, 1442, 743, 2424, 4, 8815, 418, 70, 637, 69, 237, 94, 541, 8815, 26055, 26056, 120, 1, 8815, 323, 8, 47, 20, 323, 167, 10, 207, 633, 635, 2, 116, 291, 382, 121, 15535, 3315, 1501, 574, 734, 10013, 923, 11578, 822, 1239, 1408, 360, 8815, 221, 15, 576, 8815, 22224, 2274, 13426, 734, 10013, 27, 28606, 340, 16, 41, 18687, 1500, 388, 11243, 165, 3962, 8815, 115, 627, 499, 79, 4, 8815, 1430, 380, 2163, 114, 1919, 2503, 574, 17, 60, 100, 4875, 5100, 260, 1268, 26057, 15, 574, 493, 744, 637, 631, 3, 394, 164, 446, 114, 615, 3266, 1160, 684, 48, 1175, 224, 1, 16, 4, 8815, 3, 507, 62, 25, 16, 640, 133, 231, 95, 7426, 600, 3439, 8815, 37248, 1864, 1, 128, 342, 1442, 247, 3, 865, 16, 42, 1487, 997, 2333, 12, 549, 386, 717, 6920, 12, 41, 16, 158, 362, 4392, 3388, 41, 87, 225, 438, 207, 254, 117, 3, 18688, 18689, 316, 1356]
결과를 보면 텍스트로 되어 있던 첫 번째 리뷰가 각 단어의 인덱스로 바뀌었다.
이렇게 바뀐 경우 각 인덱스가 어떤 단어를 의미하는지 모르기 때문에 단어 사전을 구축해보자.
word_vocab = tokenizer.word_index
print(word_vocab)
print("전체 단어 개수: ", len(word_vocab) + 1)결과 :
{'movie': 1, 'film': 2, 'one': 3, 'like': 4, 'good': 5, 'time': 6, 'even': 7, 'would': 8, 'story': 9, 'really': 10, 'see': 11, 'well': 12, 'much': 13, 'get': 14, 'bad': 15, 'people': 16, 'also': 17, 'first': 18, 'great': 19, 'made': 20, 'way': 21, 'make': 22, 'could': 23, 'movies': 24, 'think': 25, 'characters': 26, 'character': 27, 'watch': 28, 'two': 29, 'films': 30, 'seen': 31, 'many': 32, 'life': 33, 'plot': 34, 'acting': 35, 'never': 36, 'love': 37, 'little': 38, 'best': 39, 'show': 40, 'know': 41, 'ever': 42, 'man': 43, 'better': 44, 'end': 45, 'still': 46, 'say': 47, 'scene': 48, 'scenes': 49, 'go': 50, 'something': 51, 'back': 52, 'real': 53, 'watching': 54, 'though': 55, 'thing': 56, 'old': 57, 'years': 58, 'actors': 59, 'director': 60, 'work': 61, 'another': 62, 'new': 63, 'nothing': 64, 'funny': 65, 'actually': 66, 'makes': 67, 'look': 68, 'find': 69, 'going': 70, 'part': 71, 'lot': 72, 'every': 73, 'world': 74, 'cast': 75, 'us': 76, 'quite': 77, 'want': 78, 'things': 79, 'pretty': 80, 'young': 81, ...
전체 단어 개수: 74066
위의 코드와 같이 tokenizer객체에 word_index 값을 뽑으면 사전 형태로 구성되어있다.
또한 단어 사전에 존재하는 전체 단어 개수는 74000개 정도로 이후 모델에서 사용되기 때문에 개수도 저장한다.
data_configs = {}
data_configs['vocab'] = word_vocab
data_configs['vocab_size'] = len(word_vocab)이제 마지막 전처리 과정이다.
현재 각 데이터는 서로 길이가 다른데 길이를 통일해야 모델에 바로 적용할 수 있으므로 최대 길이로 정하여 길이를 통일한다.
통일하는 방법은 최대 길이에 맞춰 뒷부분을 0 값으로 패딩 하는 작업으로 진행한다.
MAX_SEQUENCE_LENGTH = 174
train_inputs = pad_sequences(text_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
print('Shape of train data: ', train_inputs.shape)결과 :
Shape of train data: (25000, 174)
문장 최대 길이는 174로 지정하였으며 이는 앞에서 분석했던 단어 개수의 중간값이다.
pad_sequences 함수를 사용하여 데이터, 최대 길이 값, 0 값을 앞에 위치할지 뒤에 위치할지를 설정한다.
이렇게 패딩 처리를 통해 25000개의 데이터를 174의 길이로 동일하게 처리됐음을 확인할 수 있다.
이제 마지막으로 레이블을 넘 파이 배열로 저장한다.
train_labels = np.array(train_data['sentiment'])
print('Shape of label tensor:', train_labels.shape)결과 :
Shape of label tensor: (25000,)
결과를 확인해보면 25000의 벡터가 생겼음을 확인할 수 있다.
위의 과정을 그림을 통해 이해해보자.

우선 원본 텍스트 데이터를 인덱스 벡터로 변환한 후 패딩 처리를 한다.
이렇게 되면 각 리뷰가 하나의 벡터로 변환된 것을 확인할 수 있다.
이렇게 전처리 과정을 거친 데이터를 모델에 사용하기 위해 저장하자.
여기서는 총 4개의 데이터를 저장한다.
- 정제된 텍스트 데이터 : csv파일
- 벡터화한 데이터 : 넘 파이 파일
- 정답 레이블 : 넘 파이 파일
- 데이터 정보 : json파일
TRAIN_INPUT_DATA = 'train_input.npy'
TRAIN_LABEL_DATA = 'train_label.npy'
TRAIN_CLEAN_DATA = 'train_clean.csv'
DATA_CONFIGS = 'data_configs.json'
import os
# 저장하는 디렉토리가 존재하지 않으면 생성
if not os.path.exists(DATA_IN_PATH):
os.makedirs(DATA_IN_PATH)만약 폴더가 없으면 생성하는 코드까지 실행한다.
이제 지정된 경로에 데이터를 저장하자.
# 전처리 된 데이터를 넘파이 형태로 저장
np.save(open(DATA_IN_PATH + TRAIN_INPUT_DATA, 'wb'), train_inputs)
np.save(open(DATA_IN_PATH + TRAIN_LABEL_DATA, 'wb'), train_labels)
# 정제된 텍스트를 csv 형태로 저장
clean_train_df.to_csv(DATA_IN_PATH + TRAIN_CLEAN_DATA, index = False)
# 데이터 사전을 json 형태로 저장
json.dump(data_configs, open(DATA_IN_PATH + DATA_CONFIGS, 'w'), ensure_ascii=False)위의 코드를 통해 해당 경로에 파일들이 저장되었다.
여기에 추가로 뒤에서 사용할 수 있도록 각 리뷰 데이터에 대해 id값을 저장한다.
test_data = pd.read_csv(DATA_IN_PATH + "testData.tsv", header=0, delimiter="\t", quoting=3)
clean_test_reviews = []
for review in test_data['review']:
clean_test_reviews.append(preprocessing(review, remove_stopwords = True))
clean_test_df = pd.DataFrame({'review': clean_test_reviews, 'id': test_data['id']})
test_id = np.array(test_data['id'])
text_sequences = tokenizer.texts_to_sequences(clean_test_reviews)
test_inputs = pad_sequences(text_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
TEST_INPUT_DATA = 'test_input.npy'
TEST_CLEAN_DATA = 'test_clean.csv'
TEST_ID_DATA = 'test_id.npy'
np.save(open(DATA_IN_PATH + TEST_INPUT_DATA, 'wb'), test_inputs)
np.save(open(DATA_IN_PATH + TEST_ID_DATA, 'wb'), test_id)
clean_test_df.to_csv(DATA_IN_PATH + TEST_CLEAN_DATA, index = False)이렇게 전처리 과정이 끝났다.
다음 포스팅에서는 직접 모델에 적용하고 주어진 텍스트에 대해 감정 분류를 하는 모델을 만들어보도록 하자.
'정리 > 텐서플로와 머신러닝으로 시작하는 자연어처리' 카테고리의 다른 글
| Chap04. 영어 텍스트 분류_모델링 2 (0) | 2021.07.29 |
|---|---|
| Chap04. 영어 텍스트 분류_모델링 1 (0) | 2021.07.26 |
| Chap03. 자연어처리 개요_데이터 이해하기 (0) | 2021.07.13 |
| Chap03. 자연어처리 개요_텍스트 분류 및 유사도 (0) | 2021.07.07 |
| chap03. 자연어 처리 개요_단어 표현 (0) | 2021.07.06 |



