이번 포스팅은 자연어 처리를 위한 도구를 알아보는 단계이다.
도구란 자연어 처리를 위한 라이브러리를 의미하며 이번 포스팅에서 알아볼 라이브러리 종류는 다음과 같다.
1. 텐서플로 - 딥러닝 모델을 만들기 위한 라이브러리
2. 사이킷런 - 머신러닝 모델과 데이터를 다루기 위한 라이브러리
3. NLTK와 Spacy - 자연어 데이터를 토크나이징 하기 위한 라이브러리
4. 넘파이 판다스 등
[ 텐서플로-TensorFlow ]
텐서플로(TensorFlow)는 구글에서 2015년에 오픈소스로 발표한 머신러닝 라이브러리다.
일반인이 쉽게 사용할 수 있도록 구성되어 있으며 파이썬을 주로 활용해 손쉽게 모델링 및 테스트가 가능한 구조이다.
또한 적극적으로 이슈 대응 및 버전 업그레이드를 통해 인지도를 높이고 있다.
텐서플로의 특징은 다음과 같다.
- 데이터 플로우 그래프를 통한 풍부한 표현력
- 아이디어 테스트에서 서비스 단계까지 이용 가능
- 계산 구조와 목표 함수만 정의하면 자동으로 미분 계산을 처리
- 파이썬/C++를 지원하며, SWIG를 통해 다양한 언어를 지원 가능
- 유연성과 확장성
여기서 텐서(Tensor)는 N차원 매트릭스를 의미하며, 텐서를 플로우(Flow)한다는 것은 데이터 흐름 그래프를 사용해 수치 연산을 하는 과정을 의미한다.
그래프의 노드(Node)는 수치 연산, 변수, 상수를 나타내고 에지(edge)는 노드 사이를 이동하는 다차원 데이터 배열(텐서, Tensor)을 나타낸다.
텐서플로는 유연한 아키텍처로 구성되어 있어 코드를 수정하지 않아도 CPU나 GPU를 사용해 연산을 구동시킬 수 있다.
▶ tf.keras.layers
텐서플로를 이용해 하나의 딥러닝 모델을 만드는 것은 마치 블록을 하나씩 쌓아서 전체 구조를 만드는 것과 비슷하다.
따라서 쉽게 블록을 바꾸고, 블록들의 조합을 쉽게 만들 수 있다는 것은 텐서플로의 큰 장점이다.
텐서플로에는 블록 역할을 할 수 있는 모듈의 종류가 다양하며 이 다양한 모듈을 활용하여 모델을 만들 수 있다.
tf.keras.layers는 텐서플로의 케라스 모듈 중 하나이며, 이 모듈에 대해서 알아보도록 하자.
일단 케라스는 텐서플로와 같은 별개의 딥러닝 오픈소스이지만 텐서플로에서도 사용이 가능하다.
· tf.keras.layers.Dense
Dense란 신경망 구조의 가장 기본적인 형태를 의미한다.
즉, 아래의 수식을 만족하는 기본적인 신경망 형태의 층을 만드는 함수이다.

x는 입력 벡터, b는 편향 벡터이며 w는 가중치 행렬이다. 즉, 가중치와 입력 벡터를 곱한 후 편향을 더해준다.
그리고 그 값에 f라는 활성화함수를 적용하는 구조다.
위 수식을 그림으로 보면 아래와 같은 은닉층이 없는 간단한 신경망 현태가 된다.
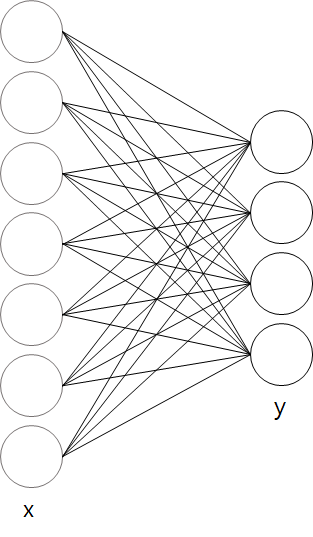
그림에서 왼쪽 노드들이 입력 값인 x가 되고 오른쪽 노드들이 y가 된다.
그리고 중간에 있는 선이 가중치를 곱하는 과정을 의미하고, 여기서 곱해지는 가중치들이 w가 된다.
이러한 과정을 구성하는 기본적인 방법은 행렬 곱을 사용하는 것이며 코드 형태는 다음과 같다.
W = tf.variable(tf.random_uniform([5,10],-1.0,1.0))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(W,x)+b다음과 같이 모든 변수들을 선언하고 하나하나 직접 곱하고, 더해야 한다.
하지만 텐서플로의 Dense를 이용하면 한 줄로 위의 코드를 작성할 수 있다.
먼저, 케라스의 Dense를 사용하려면 객체를 생성하고, 생성한 객체에 입력값을 넣는다.
입력값을 넣기 위해서는 객체를 생성할 때 함께 넣거나 생성한 후 따로 적용하는 방법이 있다.
# 1. 객체 생성 후 입력값 설정
dense = tf.keras.layers.Dense(...)
output = dense(input)
# 2. 객체 생성 시 입력값 설정
output = tf.keras.layers.Dense(...)(input)Dense층을 만들 때 여러 인자를 통해 가중치와 편향 초기화 방법, 활성화 함수의 종류 등의 옵션을 정할 수 있으며 객체 생성 시 지정할 수 있는 인자는 다음과 같다.
__init__(
units,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)각 인자값들은 다음의 의미를 가진다.
- units : 출력 값의 크기, Integer or Long
- activation : 활성화 함수
- use_bias : 편향(b)을 사용할지 여부, Boolean 형태
- kernel_initializer : 가중치(W) 초기화 함수
- bias_initializer : 편향 초기화 함수
- kernel_regularizer : 가중치 정규화 방법
- bias_regularizer : 편향 정규화 방법
- activity_regularizer : 출력 값 정규화 방법
- kernel_constraint : Optimizer에 의해 업데이트된 이후에 가중치에 적용되는 부가적인 제약 함수
(ex : norm constraint, value constraint) - bias_constraint : Optimizer에 의해 업데이트된 이후에 편향에 적용되는 부가적인 제약 함수
(ex : norm constraint, value constraint)
다음 예시를 통하여 살펴보자.
먼저, 하나의 Dense층으로 구성되어 있는 신경망으로, 20개의 입력값이 들어오고 출력 값으로 10개의 값을 출력하는 완전 연결 계층(Fully Connected Layer) 신경망이다.
INPUT_SIZE = (20, 1)
input = tf.placeholder(tf.float32, shape = INPUT_SIZE)
output = tf.keras.layers.Dense(units = 10, activation = tf.nn.sigmoid)(input) 두 번째로, 20개의 입력값과 10개의 노드를 가지는 은닉층이 있고 최종 출력 값으로 2개를 출력하는 신경망 코드이다.
INPUT_SIZE = (20, 1)
input = tf.placeholder(tf.float32, shape = INPUT_SIZE)
hidden = tf.keras.layers.Dense(units = 10, activation = tf.nn.sigmoid)(input)
output = tf.keras.layers.Dense(units = 2, activation = tf.nn.sigmoid)(hidden)
· tf.keras.layers.Dropout
신경망 모델을 만들 때 생기는 문제점 중 대표적인 문제점은 과적합(Overfitting)이다.
이를 해결하기 위해 정규화(Regularization) 방법을 사용하는데, 정규화 방법 중 하나가 드롭아웃(dropout)이다.
텐서플로에서는 드롭아웃을 쉽게 적용하도록 모듈을 제공하며, 사용법은 Dropout객체를 생성하여 사용하면 된다.
# 1. 객체 생성 후 입력값 설정
dropout = tf.keras.layers.Dropout(...)
output = dropout(input)
# 2. 객체 생성 시 입력값 설정
output = tf.keras.layers.Dropout(...)(input)드롭아웃 객체에도 다른 객체와 동일하게 인자를 설정할 수 있으며, 설정 가능한 인자들은 다음과 같다.
__init__(
rate,
noise_shape=None,
seed=None,
**kwargs
)각 인자값들은 다음의 의미를 가진다.
- rate : 드롭아웃을 적용할 확률을 지정한다. (0~1 사이의 값 지정)
(ex : dropout=0.2로 지정 시 전체 입력 값 중 20%를 0으로 만듦) - noise_shape : 정수형의 1D-tensor 값을 받는다. 여기서 받은 값은 shape을 뜻하는데, 이 값을 지정함으로써 특정 값만 드롭아웃을 적용할 수 있다.
(ex : 입력값이 이미지일 경우 noise_shape을 지정하면 특정 채널에만 드롭아웃 지정 가능함) - seed : 드롭아웃의 경우 지정된 확률 값을 바탕으로 무작위로 드롭아웃을 적용하는데, 이때 임의의 선택을 위한 시드 값을 의미한다. seed값은 정수형이며, 같은 seed 값을 가지는 드롭아웃의 경우 동일한 드롭아웃 결과를 만든다.
다음은 이전의 dense층 예제에서 입력 값에 드롭아웃을 적용한 예제이다.
INPUT_SIZE = (20, 1)
input = tf.placeholder(tf.float32, shape = INPUT_SIZE)
dropout = tf.keras.layers.Dropout(rate = 0.2)(input)
hidden = tf.keras.layers.Dense(units = 10, activation = tf.nn.sigmoid)(dropout)
output = tf.keras.layers.Dense(units = 2, activation = tf.nn.sigmoid)(hidden)위의 코드와 같이 드롭아웃을 적용하려는 층의 노드를 객체에 적용하면 된다.
이처럼 드롭아웃은 여러 층에 범용적으로 사용되어 과적합을 방지하기 때문에 모델을 구현할 대 자주 사용하는 기법이다.
· tf.keras.layers.Conv1D
tf.keras.layers.Conv1D은 합성곱(Convolution) 연산 중 Conv1D에 대한 모듈이다.
텐서플로의 합성곱 연산은 Conv1D, Conv2D, Conv3D로 나눠지며 각 차이점은 다음과 같다.

우리가 흔히 알고 있는 기본적인 이미지에 적용하는 합성곱 방식은 Conv2D다.
위의 표에서 나온 출력값의 경우 실제 합성곱 출력 값과 동일하진 않은데, 그 이유는 배치 크기와 합성곱이 적용되는 필터의 개수도 고려해야 하기 때문에 출력 값이 위와 동일하게 나오지 않는 것이다.
Conv1D를 적용하는 과정을 살펴보자.
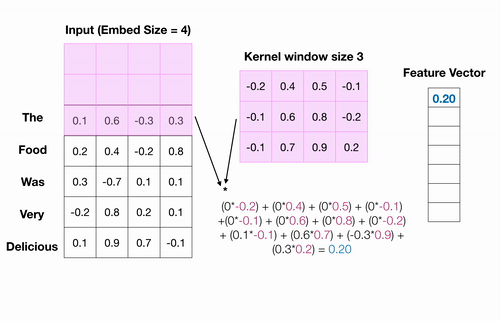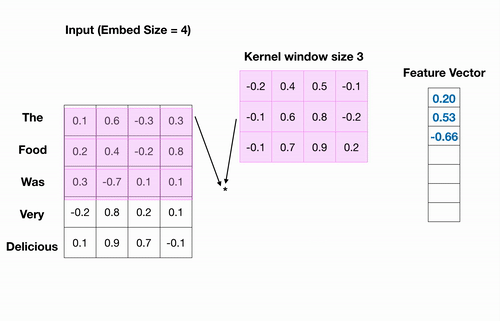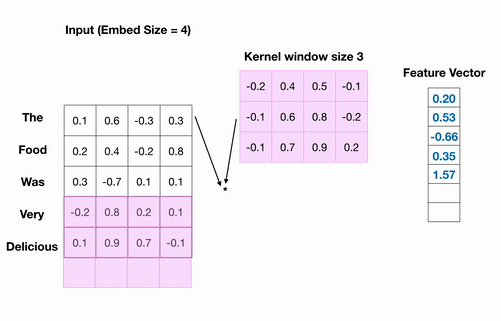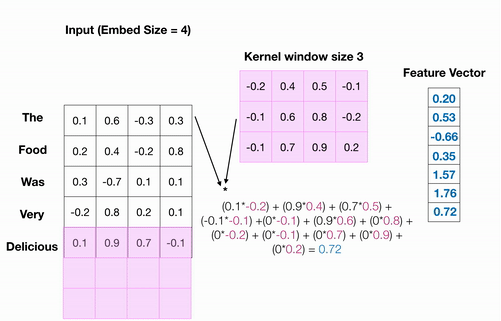
분홍색 사각형이 하나의 필터가 되어 하나씩 옮겨가면서 입력값에 대해 합성곱을 수행한다.
수행된 연산 결과들이 모여서 최종 출력 값이 나오며, 최종 출력 값은 1차원 벡터가 된 것을 확인할 수 있다.
자연어 처리 분야에서 사용하는 합성곱의 경우 각 단어(혹은 문자) 벡터의 차원 전체에 대해 필터를 적용시키기 위해 주로 Conv1D를 사용하며, Conv1D를 사용하는 방법은 다음과 같다.
# 1. 객체 생성 후 입력값 설정
conv1d = tf.keras.layers.Conv1D(...)
output = conv1d(input)
# 2. 객체 생성 시 입력값 설정
output = tf.keras.layers.Conv1D(...)(input)합성곱 또한 필터의 크기, 필터의 개수, 스트라이드 값 등을 인자로 설정할 수 있으며, 설정 가능한 인자는 다음과 같다.
__init__(
filters,
kernel_size,
strides=1,
padding='valid',
data_format='channels_last',
dilation_rate=1,
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regulatizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)구조는 이전의 Dense와 비슷하지만 합성곱 연산을 수행할 필터와 관련된 부분이 다르다.
또한 합성곱은 기본적으로 필터의 크기를 필요로 하는데, 이 경우 Conv1D는 필터의 높이(high)는 필요하지 않다. 즉, 필터의 가로에 적용되는 kernel_size와 총 몇 개의 필터를 사용할지를 filters 인자를 통해 설정하면 된다.
또한 패딩을 사용해 입력값과 출력값의 가로 크기를 똑같이 만들고 싶다면 padding="same"을 지정하면 입력과 출력의 가로 값이 같아진다. 이 밖의 인자 값들의 의미는 다음과 같다.
- filters : (정수형) 필터의 개수, 출력의 차원수를 나타냄
- kernel_size : (정수형 or 정수의 리스트 or 튜플 형태) 필터의 크기, 합성곱이 적용되는 윈도우의 길이를 나타냄
- strides : (정수형 or 정수의 리스트 or 튜플 형태) 적용할 스트라이드의 값, 1이 아닌 값을 지정할 경우 dilation_rate는 1 이외의 값을 지정할 수 없음.
- padding : 패딩 방법 지정, "VALID" OR "SAME"
- data_format : 데이터의 표현 방법 선택, " channel_last" OR "channel_first"
- "channel_last"의 경우 데이터는 (batch, length, channels) 형태여야 함.
- "channel_first"의 경우 데이터는 (batch, channels, length) 형태여야 함. - dilation_rate : (정수형 or 정수의 리스트 or 튜플 형태) dilation 합성곱 사용 시 적용할 dilation 값, 1이 아닌 값을 지정할 경우 strides는 1 이외의 값을 지정할 수 없음.
- activation : 활성화 함수
- use_bias : (Boolean형) 편향(b)을 사용할지 여부
- kernel_initializer : 가중치(W) 초기화 함수
- bias_initializer : 편향 초기화 함수
- kernel_regulatizer : 가중치 정규화 방법
- bias_regularizer : 편향 정규화 방법
- activity_regularizer : 출력 값 정규화 방법
- kernel_constraint : Optimizer에 의해 업데이트된 이후에 가중치에 적용되는 부가적인 제약 함수
(ex : norm constraint, value constraint) - bias_constraint : Optimizer에 의해 업데이트된 이후에 편향에 적용되는 부가적인 제약 함수
(ex : norm constraint, value constraint)
Conv1D을 사용한 기본적인 합성곱 신경망은 다음과 같다.
INPUT_SIZE = (1, 28, 28)
input = tf.placeholder(tf.float32, shape = INPUT_SIZE)
conv = tf.keras.layers.Conv1D(
filters=10,
kernel_size=3,
padding='same',
activation=tf.nn.relu)(input)또한 입력값에 드롭아웃을 적용한 합성곱 신경망도 다음과 같이 구현할 수 있다.
INPUT_SIZE = (1, 28, 28)
input = tf.placeholder(tf.float32, shape = INPUT_SIZE)
dropout = tf.keras.layers.Dropout(rate=0.2)(input)
conv = tf.keras.layers.Conv1D(
filters=10,
kernel_size=3,
padding='same',
activation=tf.nn.relu)(dropout)
· tf.keras.layers.MaxPool1D
합성곱 신경망과 함께 쓰이는 기법 중 하나는 풀링이다.
보통 피처 맵(feature map)의 크기를 줄이거나 주요한 특징을 뽑아내기 위해 합성곱 이후에 적용되는 기법이다.
풀링에는 주로 맥스 풀링(max-pooling)과 평균 풀링(average-pooling)이 사용된다.
맥스 풀링은 피처 맵에 대해 최대값만을 뽑아내는 방식이고, 평균 풀링은 피처 맵에 대해 전체 값들을 평균한 값을 뽑는 방식이다.
이번 포스팅에서는 맥스 풀링 기법에 대해서 알아보도록 하자.
맥스 풀링도 합성곱과 같이 세 가지 형태로 모델이 구분되어 있으며, 원리 또한 합성곱과 똑같은 원리로 MaxPool1D, MaxPool2D, MaxPool3D로 나뉘어 있다. 자연어 처리에 주로 사용되는 풀링은 MaxPool1D를 주로 사용하는데 한 방향으로만 풀링이 진행된다. 사용법은 앞에서 설명한 합성곱과 동일하다.
# 1. 객체 생성 후 입력값 설정
max_pool = tf.keras.layers.MaxPool1D(...)
output = max_pool(input)
# 2. 객체 생성 시 입력값 설정
output = tf.keras.layers.MaxPool1D(...)(input)맥스 풀링도 여러 인자 값을 설정함으로써 풀링이 적용되는 필터의 크기 등을 설정할 수있다.
__init__(
pool_size=2,
strides=None,
padding='valid',
data_format=None,
**kwargs
)인자 값들의 의미는 다음과 같다.
- pool_size : (정수형) 풀링을 적용할 필터의 크기를 나타냄
- strides : (정수형 or None) 적용할 스트라이드의 값
- padding : 패딩 방법, "valid" OR " same"
- data_format : 데이터의 표현 방법 선택, " channel_last" OR "channel_first"
- "channel_last"의 경우 데이터는 (batch, length, channels) 형태여야 함.
- "channel_first"의 경우 데이터는 (batch, channels, length) 형태여야 함.
예제를 통해 합성곱 신경망에서 맥스 풀링을 사용하는 방법을 익혀 보자.
다음 예제는 입력값이 합성곱과 맥스 풀링을 사용한 후 완전 연결 계층을 통해 최종 출력 값이 나오는 구조이다.
입력값에는 드롭아웃을 적용한다.
맥스 풀링 결괏값을 완전 연결 계층으로 연결하기 위해서 행렬이었던 것을 벡터로 만들기 위해 tf.keras.layers.Flatten을 사용한다.
Input -> Dropout -> Convolutional layer -> MaxPooling -> Dense layer with 1 hidden layer -> Output
INPUT_SIZE = (1, 28, 28)
input = tf.placeholder(tf.float32, shape = INPUT_SIZE)
dropout = tf.keras.layers.Dropout(rate = 0.2)(input)
conv = tf.keras.layers.Conv1D(
filters=10,
kernel_size=3,
padding='same',
activation=tf.nn.relu)(dropout)
max_pool = tf.keras.layers.MaxPool1D(pool_size = 3, padding = 'same')(conv)
flatten = tf.keras.layers.Flatten()(max_pool)
hidden = tf.keras.layers.Dense(units = 50, activation = tf.nn.relu)(flatten)
output = tf.keras.layers.Dense(units = 10, activation = tf.nn.softmax)(hidden) 이 밖에도 여러 모듈이 있으므로 텐서플로 홈페이지의 공식 문서에서 필요한 문서를 참고하길 바란다.
· tf.data
머신러닝에서 문제를 해결할 때 많은 시간이 데이터를 다루는 데 소요된다.
기존의 텐서플로에서 데이터를 처리하는 방식은 tf.placeholder와 tf.feed_dict를 활용해 모델에 값을 전달하는 방식이었지만 필요한 기능(데이터의 셔플, 배치, 반복 등)을 모두 직접 구현해야 하고, 최적화가 되어있지 않은 불편함이 있었다.
이를 해결하기 위해 새롭게 추가된 모듈이 tf.data로 이 모듈의 기능을 알아보자.
먼저 tf.data모듈을 활용하기 위해 예제에 필요한 모듈들을 불러온다.
import os
import tensorflow as tf #텐서플로우 모듈 불러오기
import numpy as np
from tensorflow.keras import preprocessing다음으로 예제에 사용할 텍스트 데이터를 생성한다.
데이터와 각 데이터의 라벨을 정의하였으며, 라벨은 임의로 설정한 것이므로 특별한 의미는 없다.
samples = ['너 오늘 이뻐 보인다',
'나는 오늘 기분이 더러워',
'끝내주는데, 좋은 일이 있나봐',
'나 좋은 일이 생겼어',
'아 오늘 진짜 짜증나',
'환상적인데, 정말 좋은거 같아']
label = [[1], [0], [1], [1], [0], [1]]다음은 전처리 과정이다. 전처리 과정은 뒤에서 자세히 살펴볼 것이므로 이런 구조로 진행된다는 것만 알면 될 것 같다.
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(samples)
sequences = tokenizer.texts_to_sequences(samples)
word_index = tokenizer.word_index전처리 과정이 끝나면 각 단어들은 인덱스 처리된다. 즉 텍스트 데이터를 수치화하는 과정이 전처리 과정이다.
print("수치화된 텍스트 데이터: \n",sequences)
print("각 단어의 인덱스: \n", word_index)
print("라벨: ", label) 결과 :

다음으로 수치화된 데이터를 텐서플로의 tf.data를 활용하여 처리해보자.
dataset = tf.data.Dataset.from_tensor_slices((sequences, label))
iterator = dataset.make_one_shot_iterator()
next_data = iterator.get_next()첫 번째로 tf.data.Dataset.from_tensor_slices 함수는 주어진 데이터 sequences와 label을 묶어서 조각으로 만들고 함께 사용할 수 있게 해 준다.
다음으로 make_one_shot_iterator() 함수는 데이터를 하나씩 사용할 수 있게 만들어준다.
마지막으로 get_next()를 통해 데이터가 하나씩 나오게 된다.
위의 코드를 통해 처리된 데이터를 출력해보면 다음과 같다.
with tf.Session() as sess:
while True:
try:
print(sess.run(next_data))
except tf.errors.OutOfRangeError:
break결과 :

여기서 더 이상 불러올 데이터가 없는 경우 범위를 넘어갔다는 에러가 출력되기 때문에 try/except문을 사용한다.
이처럼 tf.data는 간단하게 데이터를 모델에 적용이 가능할 뿐만 아니라 데이터의 셔플, 배치, 반복, 매핑과 같은 여러 기능들을 간단히 구현이 가능하다.
BATCH_SIZE = 2
EPOCH = 2
def mapping_fn(X, Y=None):
input = {'x': X}
label = Y
return input, label
dataset = tf.data.Dataset.from_tensor_slices((sequences, label))
dataset = dataset.map(mapping_fn) # 매핑함수
dataset = dataset.shuffle(len(sequences)) # 셔플함수
dataset = dataset.batch(BATCH_SIZE) #배치함수
dataset = dataset.repeat(EPOCH) #에폭함수
iterator = dataset.make_one_shot_iterator()
next_data = iterator.get_next()
with tf.Session() as sess:
while True:
try:
print(sess.run(next_data))
except tf.errors.OutOfRangeError:
break결과 :

▶ 에스티메이터(Estimator)
딥러닝 모델을 최대한 빠르게 실험해보고 다양한 모델을 적용해야 하는 연구자와 개발자들은 모델 구현에 집중할 수 있는 환경이 중요한데, 이러한 욕구를 충족시켜줄 수 있는 기능이 텐서플로의 에스티메이터이다.
에스티메이터는 고수준(High-Level) API로 모델 구현에만 집중할 수 있는 환경을 제공한다.
모델 구현 외의 학습(Train), 검증(Evaluate), 예측(Predict), 배포(Export)에 필요한 부가적인 구현은 Estimator의 함수를 사용함으로써 손쉽게 사용할 수 있다.
즉, 에스티메이터에서 기본적으로 제공하는 기능은 다음과 같다.
- 학습(Train) : 정의한 모델 파라미터에 대해 학습한다.
- 검증(Evaluate) : 학습한 모델에 대한 성능을 측정한다.
- 예측(Predict) : 모델을 통해 입력값에 대한 예측값을 받는다.
- 배포(Export) : 사용할 모델을 바이너리 파일로 출력한다.
이외에도 선형 회귀, 선형 분류, 심층 신경망 분류기, 심층 신경망 회귀 모델 등 기본적인 모델이 이미 구현되어 있어 바로 사용이 가능하다.
이번 포스팅에서는 간단한 예제를 통해 에스티메이터에 대해 알아본 후 뒤에서 자세히 알아보도록 하자.
우선 에스티메이터를 구현하기 위해서는 기본적으로 두 가지 함수를 구현해야 한다.
첫 번째는 사용할 모델을 구현한 모델 함수이며 두 번째는 모델에 적용될 데이터를 에스티메이터에 전달하기 위한 데이터 입력 함수를 구현해야 한다.
두 함수 모두 올바르게 동작하기 위해서는 정해진 형식을 맞춰서 구현해야 하며, 정해진 형식은 다음과 같다.
1. 모델 함수
def model_fn(features, labels, mode, params, config):
# 모델 구현 부분
return tf.estimator.EstimatorSpec(...)모델 함수의 인자는 총 5개이며 각 인자에 대한 설명은 다음과 같다.
- features [필수] : (하나의 텐서 자료형 or 딕셔너리 자료형) 모델에 적용되는 입력값을 의미, 학습, 검증, 예측 과정에 모두 사용
- labels [필수] : (하나의 텐서 자료형 or 딕셔너리 자료형) 모델의 정답 라벨 값을 의미, 예측 과정은 라벨이 존재하지 않기 때문에 Estimator에서 자동으로 이 값이 들어오지 않음
- mode : 현재 모델 함수가 실행된 모드(학습, 검증, 예측)를 의미
- params : (딕셔너리 자료형) 모델에 적용될 부가적인 하이퍼 파라미터 값을 의미
- config : 모델에 적용할 설정값을 의미
다음과 같이 생성된 모델 함수를 Estimator 객체에 적용하면 된다. 에스티메이터 객체의 경우 아래와 같이 생성한다.
estimator = tf.estimator.Estimator(model_fn = model_fn, model_dir = ..., configs = ..., params = ...)모델 함수의 경우 필수적으로 입력해줘야 하고, 나머지 값들은 필요에 따라 선택적으로 넣어주면 된다.
객체 생성이 완료되었으면 다음과 같이 객체의 함수를 사용해 실행할 수 있다.
# 모델 학습
estimator.train(input_fn=...)
# 모델 검증
estimator.evaluate(input_fn=...)
# 모델 예측
estimator.predict(input_fn=...)2. 입력 함수
입력 함수의 경우 다음 형식에 따라 구현해주면 된다.
def train_input_fn():
#데이터 파이프라인 구현 부분
return features, labels데이터 파이프라인 구현 부분에는 데이터의 셔플, 배치, 반복 등의 기능들이 들어갈 것이다.
이제 에스티메이터를 사용해서 간단한 신경망 모델을 구현해 보자.
구현할 모델은 심층 신경망 구조를 사용해서 텍스트의 긍/부정을 예측하는 감정 분석 모델이다.
모델의 전체적 구조는 다음과 같다.

각 단어로 구성된 입력값은 임베딩 된 벡터로 변형되고, 각 벡터를 평균해서 하나의 벡터로 만들어준다.
이후에 하나의 은닉층을 거친 후 하나의 결괏값을 뽑는 구조이다.
마지막으로 나온 결괏값에 시그모이드 함수를 적용해 0과 1 사이의 값을 구한다.
모델에서 나온 임베딩 벡터 등과 같은 내용이 잘 이해되지 않아도 대략적인 모델의 구조만 이해하고 넘어가자.
(자세한 내용은 뒤에서!!)
이제 본격적으로 모델을 구현해보자.
데이터는 tf.data의 텍스트 데이터를 그대로 사용하고, 동일하게 전처리 과정을 적용한다.
import tensorflow as tf
from tensorflow.keras import preprocessing
samples = ['너 오늘 이뻐 보인다',
'나는 오늘 기분이 더러워',
'끝내주는데, 좋은 일이 있나봐',
'나 좋은 일이 생겼어',
'아 오늘 진짜 짜증나',
'환상적인데, 정말 좋은거 같아']
labels = [[1], [0], [1], [1], [0], [1]]
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(samples)
sequences = tokenizer.texts_to_sequences(samples)
word_index = tokenizer.word_index다음으로 에스티메이터의 입력 함수를 정의한다.
tf.data의 반복과 셔플 기능을 사용하고, 정의한 에폭 크기만큼 데이터를 반복시켜 학습하고 셔플 기능을 추가해 모델이 학습을 잘할 수 있도록 한다.
그리고 데이터 입력 함수의 반환 값은 이터레이터의 get_next()함수를 사용하여 입력값과 라벨 값을 반환한다.
EPOCH = 100
def train_input_fn():
dataset = tf.data.Dataset.from_tensor_slices((sequences, labels))
dataset = dataset.repeat(EPOCH)
dataset = dataset.batch(1)
dataset = dataset.shuffle(len(sequences))
iterator = dataset.make_one_shot_iterator()
return iterator.get_next()다음으로 모델 함수를 정의한다.
VOCAB_SIZE = len(word_index) +1
EMB_SIZE = 128
def model_fn(features, labels, mode):
TRAIN = mode == tf.estimator.ModeKeys.TRAIN
EVAL = mode == tf.estimator.ModeKeys.EVAL
PREDICT = mode == tf.estimator.ModeKeys.PREDICT
embed_input = tf.keras.layers.Embedding(VOCAB_SIZE, EMB_SIZE)(features)
embed_input = tf.reduce_mean(embed_input, axis=-1)
hidden_layer = tf.keras.layers.Dense(128, activation=tf.nn.relu)(embed_input)
output_layer = tf.keras.layers.Dense(1)(hidden_layer)
output = tf.nn.sigmoid(output_layer)
loss = tf.losses.mean_squared_error(output, labels)
if TRAIN:
global_step = tf.train.get_global_step()
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss, global_step)
return tf.estimator.EstimatorSpec(
mode=mode,
train_op=train_op,
loss=loss)모델 함수에서 사용될 상수값을 정의한 후 모델 함수를 구현한다.
정의한 함숫값은 전체 단어 개수와 임베딩 벡터의 크기를 나타낸다.
다음으로 모델 함수의 인자로 입력값과 라벨, 현재 모델 함수의 모드 값을 받는다.
현재 실행된 모드가 어떤 상태인지 확인하기 위하여 현재 모드를 나타내는 상수값을 정의하여 해당하는 상태의 상수값이 True로 설정되도록 한다.
다음으로 입력값을 임베딩 벡터 형태로 만든 후 텐서플로의 reduce_mean 함수를 통해 평균을 구해 하나의 입력 벡터로 만든다.
이제 이 입력값을 Dense를 사용해 은닉층을 거쳐 출력 값을 만든다.
최종적으로 나온 출력 값에 시그모이드 함수를 적용해 0과 1 사이의 값으로 만들어 모델의 최종 출력 값이 나온다.
마지막으로 학습 상태일 대 모델을 학습할 수 있도록 손실(loss) 값과 옵티마이저(optimizer)를 설정한다.
설정한 두 값을 학습 모드인 경우 EstimatorSpec의 인자 값으로 반환하면 모델 함수 구현이 끝난다.
정의한 데이터 입력 함수와 모델 함수를 에스티메이터에 적용하면 다음과 같다.
DATA_OUT_PATH = './data_out/'
import os
if not os.path.exists(DATA_OUT_PATH):
os.makedirs(DATA_OUT_PATH)
estimator = tf.estimator.Estimator(model_fn = model_fn, model_dir = DATA_OUT_PATH + 'checkpoint/dnn')결과 :

결과를 보면 손실 값이 줄어드는 것을 확인할 수 있으며, 위와 같이 학습을 거친 후 손실값이 더는 떨어지지 않는다면 이제 학습한 모델을 사용해 검증과 예측을 하면 된다.
'정리 > 텐서플로와 머신러닝으로 시작하는 자연어처리' 카테고리의 다른 글
| chap03. 자연어 처리 개요_단어 표현 (0) | 2021.07.06 |
|---|---|
| chap02. 자연어 처리 개발 준비_numpy, pandas, matplotlib, Re, Beautiful Soup (0) | 2021.07.05 |
| chap02. 자연어 처리 개발 준비_전처리 라이브러리 (0) | 2021.07.05 |
| chap02. 자연어 처리 개발 준비_사이킷런(Scikit-learn) (0) | 2021.07.01 |
| chap01. 들어가며 (0) | 2021.06.29 |



