이번 포스팅은 자연어 처리를 위한 도구 중 사이킷런에 대한 내용이다.
[사이킷런(scikit-learn)]
사이킷런(scikit-learn)은 머신러닝 기술을 활용하는 데 필요한 다양한 기능을 제공하며, 파이썬으로 머신러닝 모델을 만들 수 있는 최적의 라이브러리다.
사이킷런 라이브러리는 지도 학습 모듈, 비지도 학습 모듈, 모델 선택과 평가 모듈, 데이터 변환 모듈로 이루어져 있으며 종류는 다음과 같다.
- 지도 학습 모듈 종류
: 나이브 베이즈(Naive Bayes), 의사결정 트리(Decision Trees), 서포트 벡터 머신(Support Vector Machines) 모델 등
- 비지도 학습 모듈 종류
: 군집화(Clustering), 가우시안 혼합 모델(Gaussian mixture models) 등
- 모델 선택과 평가 모듈 종류
: 교차 검증(Cross validation), 모델 평가(Model evaluation), 모델 저장과 불러오기 기능 등
- 데이터 변환 모듈 종류
: 파이프라인(Pipeline), 특징 추출(Feature extraction), 데이터 전처리(preprocessing data), 차원 축소(dimensionality reduction) 등
아래의 그림은 사이킷런에서 제공하는 올바른 알고리즘 선택을 위한 지도이므로 참고하면 좋을 것 같다.

▶ 사이킷런 설치
사이킷런의 경우 의존성 라이브러리가 존재한다.
의존성 라이브러리란 현재 라이브러리를 사용하기 위해 미리 설치되어 있어야 하는 라이브러리를 의미한다.
사이킷런의 의존성 라이브러리는 넘파이(Numpy)와 사이파이(Scipy)가 있으며, 두 라이브러리를 먼저 설치해야 하지만 아나콘다를 통해 설치한다면 자동으로 의존성 라이브러리까지 설치가 가능하다.
아나콘다를 활용한 명령어는 다음과 같다.
conda install scikit-learn설치가 완료되면 다음 코드를 통해 정상적으로 설치가 완료되었는지, 나아가 사이킷런 라이브러리의 버전까지 확인할 수 있다.
import sklearn
sklearn.__version__
▶ 데이터 소개
사이킷런을 활용하여 모델을 만들기 위해 사용할 데이터에 대해 알아보자.
이번 포스팅에서 사용할 데이터는 머신러닝 기초에서 흔히 사용되는 붓꽃(Iris) 데이터이다.
붓꽃 데이터는 사이킷런 라이브러리에 기본적으로 내장되어 있는 데이터 중 하나이므로 따로 설치할 필요가 없다.
붓꽃 데이터를 불러오는 명령어는 다음과 같다.
from sklearn.datasets import load_iris다음으로 데이터를 변수에 할당하고, 데이터가 어떤 값으로 구성되어 있는지 확인한다.
iris_dataset = load_iris()
print(f"iris_dataset key: {iris_dataset.keys()}")결과 :
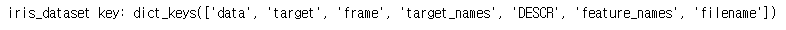
사이킷런의 붓꽃(Iris) 데이터는 다음과 같이 구성되어 있다.
각각 하나씩 확인해보면 다음과 같다.
* data
print(iris_dataset['data'])
print("shape of data: {}". format(iris_dataset['data'].shape))결과 :


data는 실제 데이터를 말하며 각 데이터마다 4개의 특징(feature) 값을 가지고 있다.
데이터의 형태를 보면 (150, 4)로 전체 150개의 데이터가 각각 4개의 특징 값을 가지고 있는 형태이다.
* feature_names
print(iris_dataset['feature_names'])결과 :
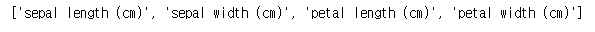
feature_names는 4개의 특징 값이 의미하는 바를 나타내며 꽃의 꽃받침 길이, 꽃받침 너비, 꽃잎 길이, 꽃잎 너비를 의미하는 것을 알 수 있다.
* target
print(iris_dataset['target'])결과 :

target은 각 데이터에 대한 정답(레이블)을 나타낸다.
결과를 보면 해당 데이터는 총 3개의 레이블을 가지고 있는 것을 알 수 있다.
* target_names
print(iris_dataset['target_names'])결과 :
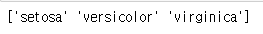
target_names는 정답(레이블) 값이 의미하는 것을 알 수 있다.
타겟은 붓꽃의 세 가지 종인 Setosa, Versicolor, Virginica를 나타내는 각 값인 0, 1, 2를 가진다.
* DESCR
print(iris_dataset['DESCR'])결과 :

DESCR은 Description의 약자로서 해당 데이터에 대한 전체적인 요약 정보를 보여준다.
이제 붓꽃 데이터를 활용하여 분류하는 모델을 만들고, 만든 모델에 대하여 평가를 진행한다.
그러기 위해 먼저 150개의 데이터중 일부를 평가를 위한 데이터로 분리하는 과정을 진행한다.
▶ 사이킷런을 이용한 데이터 분리
사이킷런을 이용하면 다음 함수를 사용하여 학습 데이터와 평가 데이터로 쉽게 나눌 수 있다.
from sklearn.model_selection import train_test_splittrain_test_split 함수에 지정할 수 있는 파라미터는 다음과 같다.
train_test_split(arrays, test_size, train_size, random_state, shuffle, stratify)각 파라미터에 대한 설명은 다음과 같다.
- arrays : 분할시킬 데이터
- test_size : 테스트 데이터셋의 비율(float)이나 갯수(int) (default = 0.25)
- train_size : 학습 데이터셋의 비율(float)이나 갯수(int) (default = test_size의 나머지)
- random_state : 데이터 분할 시 셔플이 이루어지는데 이를 위한 시드 값 (int나 RandomState로 입력)
- shuffle : 셔플 여부 설정 (default = True)
- stratify : 지정한 Data의 유지 비율
(ex : label set가 25%의 0과 75%의 1로 이루어진 Binary Set일 때, stratify=Y로 설정하면 나누어진 데이터셋들도 0과 1을 각각 25%, 75%로 유지한 채 분할됨)
train_test_split 함수를 사용하여 붓꽃 데이터를 2:1의 비율로 학습 데이터와 평가 데이터로 나누는 코드는 다음과 같다.
target = iris_dataset['target']
train_input, test_input, train_label, test_label = train_test_split(iris_dataset['data'],
target,
test_size = 0.25,
random_state=42)함수를 통해 나뉜 데이터는 지정한 변수에 대입되었으며, 각 변수의 형태는 다음과 같다.
print("shape of train_input: {}".format(train_input.shape))
print("shape of test_input: {}".format(test_input.shape))
print("shape of train_label: {}".format(train_label.shape))
print("shape of test_label: {}".format(test_label.shape))결과 :

결과를 보면 학습 데이터는 총 112개이고 평가 데이터는 38개이다.
앞에서 설정한 25%가 잘 반영된 것을 확인할 수 있다.
▶ 사이킷런을 이용한 지도 학습
지도 학습은 모델이 예측하는 결과를 각 데이터의 정답과 비교해서 모델을 반복적으로 학습시키는 것으로
이번 포스팅에서는 다양항 모델 중 간단하면서도 데이터 특성만 맞으면 좋은 결과를 확인할 수 있는 k-최근접 이웃 분류기(K-nearest neighbor classifier)를 사용할 것이다.
k-최근접 이웃 분류기(K-nearest neighbor classifier)는 예측하고자 하는 데이터에 대해 가장 가까운 거리에 있는 데이터의 라벨과 같다고 예측하는 방법으로 데이터에 대한 사전 지식이 없는 경우에 많이 사용된다.
여기서 k는 몇 개의 데이터를 참고할 것인지를 의미한다. 아래의 그림을 참고하면 더 이해하기 쉬울 것이다.

이러한 k-최근접 이웃 분류기의 특징은 다음과 같다.
- 데이터에 대한 가정이 없어 단순하다.
- 다목적 분류와 회귀에 좋다.
- 높은 메모리를 요구한다.
- k값이 커지면 계산이 늦어질 수 있다.
- 관련 없는 기능의 데이터의 규모에 민감하다.
k-최근접 이웃 분류기를 구현하는 방법은 다음과 같다.
먼저 분류기 객체를 변수에 할당한다.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 1)분류기 생성 시 n_neighbors는 k값을 의미한다. 즉, 위의 코드는 k=1인 분류기를 생성하였다.
이제 생성한 분류기를 학습 데이터에 적용한다.
knn.fit(train_input, train_label)위와 같이 fit 함수를 사용하여 분류기 모델에 학습 데이터와 레이블 값을 적용하기만 하면 모델 학습이 종료된다.
이제 학습된 모델을 통해 새로운 데이터의 레이블을 예측한다.
새롭게 4개의 feature값을 임의로 생성하여 생성한 데이터에 대해 예측해보자.
import numpy as np
new_input = np.array([[6.1, 2.8, 4.7, 1.2]])
knn.predict(new_input)결과 : array([1])
생성한 값을 대상으로 분류기 모델의 predict함수를 사용하여 결과를 예측하였다.
결과는 1로 Versicolor로 예측하고 있음을 확인하였다.
(주의 : 배열 생성 시 리스트 안에 또 하나의 리스트가 포함된 방식으로 만들었는데, 이렇게 만들지 않고 하나의 리스트만 사용할 경우 이를 함수에 적용하면 오류가 발생하므로 주의하자.)
이제 평가 데이터를 사용하여 모델의 성능을 측정해보자.
먼저 평가 데이터에 대해 예측을 하고 그 결괏값을 변수에 저장한다.
predict_label = knn.predict(test_input)
print(predict_label)결과 : [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 1 0]
이제 예측한 결괏값과 실제 결괏값을 비교하여 정확도를 측정해보자.
print('test accuracy {:.2f}'.format(np.mean(predict_label == test_label)))결과 : test accuracy 1.00
결과는 100%로 매우 좋은 성능을 보인다.
이는 데이터 자체가 특징이 구분이 잘 되고 모델이 데이터에 매우 적합한 것을 의미한다.
▶ 사이킷런을 이용한 비지도 학습
비지도 학습이란 데이터에 대한 정답(레이블)을 사용하지 않는 학습 방법으로 모델을 통해 문제를 해결하고 싶지만 정답이 없는 경우에 적용하기 적합한 모델이다.
비지도학습 방법도 여러 가지 방법이 있지만 그중 하나인 k-평균 군집화(K-means Clustering) 모델을 사용할 것이다.
군집(clustering)이란 데이터를 특성에 따라 여러 집단으로 나누는 방법을 말하며, k-평균 군집은 군집화 방법 중 가장 간단하고 널리 사용되는 군집화 방법이다.
k-평균 군집의 알고리즘은 다음과 같은 과정으로 수행된다.
- 데이터셋에서 K 개의 중심을 임의로 지정한다.
- 각 데이터들을 가장 가까운 중심이 속한 그룹에 할당한다.
- 2번 과정에서 할당된 결과를 바탕으로 중심을 새롭게 지정한다.
- 2 ~ 3번 과정을 중심이 더 이상 변하지 않을 때까지 반복한다.

이제 사이킷런 라이브러리의 k-평균 군집화 함수를 사용하여 붓꽃 데이터를 군집화해보자.
사용법은 위의 k-최근접 이웃 분류기와 비슷하다.
먼저 군집화 모듈에서 KMeans를 불러와 k-평균 군집화 모델을 만든다.
from sklearn.cluster import KMeans
k_means = KMeans(n_clusters=3)이때 인자로 k값을 의미하는 군집의 개수를 설정한다.
다음으로 군집화 모델에 데이터를 적용한다.
k_means.fit(train_input)이전과 같이 fit함수를 사용하는데, 비지도 학습이기 때문에 학습 데이터만 입력하여 데이터를 군집화한다.
레이블 값이 없이 학습이 완료된 모델의 레이블 속성(군집 속성)을 확인해 보자.
k_means.labels_결과 :
array([1, 1, 2, 2, 2, 1, 1, 2, 2, 0, 2, 0, 2, 0, 2, 1, 0, 2, 1, 1, 1, 2, 2, 1, 1, 1, 2, 1, 2, 0, 1, 2, 2, 1, 2, 2, 2, 2, 0, 2, 1, 2, 0, 1, 1, 2, 0, 1, 2, 1, 1, 2, 2, 0, 2, 0, 0, 2, 1, 1, 2, 0, 1, 1, 1, 2, 0, 1, 0, 0, 1, 2, 2, 2, 0, 0, 1, 0, 2, 0, 2, 2, 2, 1, 2, 2, 1, 2, 0, 0, 1, 2, 0, 0, 1, 0, 1, 0, 0, 0, 2, 0, 2, 2, 2, 2, 1, 2, 2, 1, 2, 0])
이는 각 데이터에 대한 레이블을 의미하는 것이 아니라 3개의 군집을 의미한다.
따라서 각 군집의 붓꽃 종의 분포를 확인하기 위해 다음과 같이 작성해서 각 군집의 종을 확인해보자.
print("0 cluster:", train_label[k_means.labels_ == 0])
print("1 cluster:", train_label[k_means.labels_ == 1])
print("2 cluster:", train_label[k_means.labels_ == 2])결과 :
0 cluster: [2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 1 2 2 2 2]
1 cluster: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
2 cluster: [2 1 1 1 2 1 1 1 1 1 2 1 1 1 2 2 2 1 1 1 1 1 2 1 1 1 1 2 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 2 2 1 2 1]
결과를 보면 0번째 군집에는 레이블 2인 데이터들이, 1번째 군집은 레이블 0인 데이터들이 분포되어 있으며 2번째 군집에는 레이블 1인 데이터들이 분포되어 있다.
위의 결과는 군집화를 진행할 때마다 바뀌는데, 그 이유는 군집화 모델 알고리즘 특성 때문에 불가피하게 발생하는 현상이다.
다음으로 임의의 새로운 데이터를 만들어서 예측을 진행해보자.
import numpy as np
new_input = np.array([[6.1, 2.8, 4.7, 1.2]])
prediction = k_means.predict(new_input)
print(prediction)결과 : [2]
결과를 보면 2번째 군집에 포함된다고 예측하였다.
마지막으로 모델의 성능을 측정하기 위해 평가 데이터를 적용하여 실제 레이블과 비교하여 성능을 측정해보자.
predict_cluster = k_means.predict(test_input)
print(predict_cluster)결과 : [2 1 0 2 2 1 2 0 2 2 0 1 1 1 1 2 0 2 2 0 1 2 1 0 0 0 0 0 1 1 1 1 2 1 1 2 2 1]
평가 데이터를 적용시켜 예측한 군집을 이제 각 붓꽃의 종을 의미하는 레이블 값으로 다시 바꿔줘야 실제 레이블과 비교해서 성능을 측정할 수 있다.
np_arr = np.array(predict_cluster)
np_arr[np_arr==0], np_arr[np_arr==1], np_arr[np_arr==2] = 3, 4, 5
np_arr[np_arr==3] = 2
np_arr[np_arr==4] = 0
np_arr[np_arr==5] = 1
predict_label = np_arr.tolist()
print(predict_label)결과 :
[2, 0, 1, 2, 2, 0, 2, 1, 2, 2, 1, 0, 0, 0, 0, 2, 1, 2, 2, 1, 0, 2, 0, 1, 1, 1, 1, 1, 0, 0, 0, 0, 2, 0, 0, 2, 2, 0]
각 데이터가 속한 군집의 순서를 실제 붓꽃의 레이블로 바꿔주었다.
0번째 군집은 레이블 2(Virginica), 1번째 군집은 레이블 0(Setosa), 2번째 군집은 레이블 1(Versicolour)을 의미한다.
이를 변경할 때는 임시 저장을 위해 군집의 순서 값 3, 4, 5를 넘파이 배열로 먼저 만들고 군집 3을 2로, 군집 4를 0으로, 군집 5를 1로 바꿔주었다.
이제 모델의 정확도를 확인해보자.
print('test accuracy {:.2f}'.format(np.mean(predict_label == test_label)))결과 : test accuracy 0.95
결과를 보면 지도 학습보다는 낮은 성능이지만 95%라는 매우 높은 성능을 보여준다.
데이터의 레이블을 사용하지 않고 학습했음에도 불구하고 이런 성능이면 매우 우수한 결과라고 할 수 있다.
▶ 사이킷런을 이용한 특징 추출
자연어 처리에서 특징 추출이란 텍스트 데이터에서 단어나 문장들을 어떤 특징 값으로 바꿔주는 것을 의미한다.
기존에 문자로 구성되어 있던 데이터를 모델에 적용할 수 있도록 특징을 추출하여 수치화한다.
이러한 과정들을 사이킷런을 사용해 처리하는 방법에 대해 알아본다.
관련 모듈은 총 3가지로 모두 텍스트를 벡터로 만드는 방법이다.
- CountVectorizer : 횟수를 기준으로 특징을 추출하는 방법
- TfidfVectorizer : TF-IDF라는 값을 사용하여 특징을 추출하는 방법
- HashingVectorizer : CountVectorizer와 동일한 방법이지만 해시 함수를 사용하여 실행 시간을 크게 단축시킴
이 중 CountVectorizer와 TfidfVectorizer에 대하여 알아보도록 하자.
- CountVectorizer
CountVectorizer는 텍스트 데이터에서 횟수를 기준으로 특징을 추출하는 방법으로 어떤 단위(단어, 문자 등)의 횟수를 셀 것인지는 선택 사항이다.
이 모듈을 사용하려면 먼저 객체를 만들고, 만들어진 객체에 특정 텍스트를 횟수를 셀 단어의 목록을 만들어야 한다.
그다음에 횟수를 기준으로 해당 텍스트를 벡터화한다. 글로만 이해하긴 어려우니 코드를 통하여 이해해보자.
우선 특징 추출 모듈(sklearn.feature_extraction.text)에서 CountVectorizer를 불러온다.
from sklearn.feature_extraction.text import CountVectorizer다음으로 텍스트 데이터를 불러온다. 그리고 CountVectorizer객체를 생성한다.
text_data = ['나는 배가 고프다', '내일 점심 뭐먹지', '내일 공부 해야겠다', '점심 먹고 공부 해야지']
count_vectorizer = CountVectorizer()그 다음 단어 사전을 만든다.
단어 사전은 생성한 객체에 fit 함수를 사용해 데이터를 적용하면 자동으로 단어 사전이 만들어진다.
count_vectorizer.fit(text_data)
print(count_vectorizer.vocabulary_)결과 : {'나는': 2, '배가': 6, '고프다': 0, '내일': 3, '점심': 7, '뭐 먹지': 5, '공부': 1, '해야겠다': 8, '먹고': 4, '해야지': 9}
단어 사전을 출력해보면 각 단어에 대해 숫자들이 사전 형태로 구성되어 있는 것을 볼 수 있다.
이제 이 텍스트 데이터를 벡터화하면 된다.
정의한 텍스트 데이터 중에서 하나만 선택하여 벡터로 만든다.
sentence = [text_data[0]] # ['나는 배가 고프다']
print(count_vectorizer.transform(sentence).toarray())결과 : [[1 0 1 0 0 0 1 0 0 0]]
각 단어가 한 번씩 나왔으므로 해당 단어 사전 순서에 맞게 1의 값을 가진다.
이처럼 내우 간단하게 특징을 추출할 수 있다.
이처럼 CountVectorizer는 직관적이고 간단해서 여러 상황에서 사용할 수 있다는 장점이 있지만 단순히 횟수만을 특징으로 잡기 때문에 큰 의미가 없지만 자주 사용되는 단어들이 높은 특징 값을 가지기 때문에 유의미하게 사용하기 어렵다는 단점이 존재한다.
이러한 문제점을 해결할 수 있는 방법이 TF-IDF방식의 TfidfVectorizer이다.
- TfidfVectorizer
TfidfVectorizer는 TF-IDF라는 특정한 값을 사용하여 특징을 추출하는 방법이다.
TF(Term Frequency)란 특정 단어가 하나의 데이터 안에서 등장하는 횟수를 의미하며, DF(Document Frequency)는 문서 빈도 값으로, 특정 단어가 여러 데이터에 자주 등장하는지를 알려주는 지표다. IDF는 DF의 값에 역수를 취해서 구할 수 있으며, 특정 단어가 다른 데이터에 등장하지 않을수록 값이 커진다는 것을 의미한다.
즉, TF-IDF는 이 두 값을 곱해서 사용하기 때문에 어떤 단어가 해당 문서에는 자주 등장하지만 다른 문서에는 많이 없는 단어일수록 높은 값을 가지게 된다.
이러한 특징을 가진 TfidfVectorizer를 사이킷런에서 활용하는 방법을 알아보자.
먼저, 위와 같은 방식으로 특징 추출 모듈에서 TfidfVectorizer를 불러온다.
from sklearn.feature_extraction.text import TfidfVectorizer다음으로 추출할 데이터를 정의하고 해당 객체를 생성한다.
text_data = ['나는 배가 고프다', '내일 점심 뭐먹지', '내일 공부 해야겠다', '점심 먹고 공부 해야지']
tfidf_vectorizer = TfidfVectorizer()TfidfVectorizer 또한 위와 동일하게 단어 사전을 구축하고 벡터화한다.
tfidf_vectorizer.fit(text_data)
print(tfidf_vectorizer.vocabulary_)
sentence = [text_data[3]] # ['점심 먹고 공부 해야지']
print(tfidf_vectorizer.transform(sentence).toarray())결과 :
{'나는': 2, '배가': 6, '고프다': 0, '내일': 3, '점심': 7, '뭐먹지': 5, '공부': 1, '해야겠다': 8, '먹고': 4, '해야지': 9}
[[0. 0.43779123 0. 0. 0.55528266 0. 0. 0.43779123 0. 0.55528266]]
단어 사전은 앞에서 만든 것과 동일한데, 벡터 값이 CountVectorizer와는 다른 것을 확인하였다.
이처럼 특징 추출 방법으로 TF-IDF를 사용할 경우 단순 횟수를 이용하는 것보다 각 단어의 특성을 좀 더 반영할 수 있다.
'정리 > 텐서플로와 머신러닝으로 시작하는 자연어처리' 카테고리의 다른 글
| chap03. 자연어 처리 개요_단어 표현 (0) | 2021.07.06 |
|---|---|
| chap02. 자연어 처리 개발 준비_numpy, pandas, matplotlib, Re, Beautiful Soup (0) | 2021.07.05 |
| chap02. 자연어 처리 개발 준비_전처리 라이브러리 (0) | 2021.07.05 |
| chap02. 자연어 처리 개발 준비_TensorFlow (0) | 2021.06.30 |
| chap01. 들어가며 (0) | 2021.06.29 |



