이번 포스팅은 딥러닝 분야의 컨볼루션 신경망에 대해 실습하면서 알아보자.
컨볼루션 신경망은 합성곱 신경망(CNN)이라고도 하며, 전통적인 신경망 앞에 여러 계층의 합성곱 계층을 쌓은 모델이다.
이는 입력 값에 대해 가장 좋은 특징을 만들어 내도록 학습하고, 추출된 특징을 활용해 분류하는 방식이다.일반적으로 이미지에서 많이 활용하였는데, 2014년 Yoon Kim 박사가 쓴 논문을 통해 텍스트에서도 좋은 효과를 낼 수 있다는 것을 입증하였다.
앞에서 본 RNN은 단어의 입력 순서를 중요하게 반영한다면 CNN은 문장의 지역 정보를 보존하면서 문장 성분의 등장 정보를 학습에 반영하는 구조이다.
이 모델을 구현하는 방법은 이전 포스팅인 RNN에서 설명했던 에스티메이터의 구조를 그대로 사용할 수 있으며, 모델쪽 코드만 변경한다면 손쉽게 CNN을 활용해 적용이 가능하다.
먼저 구현하기 전 CNN의 아키텍처를 보면 다음과 같다.
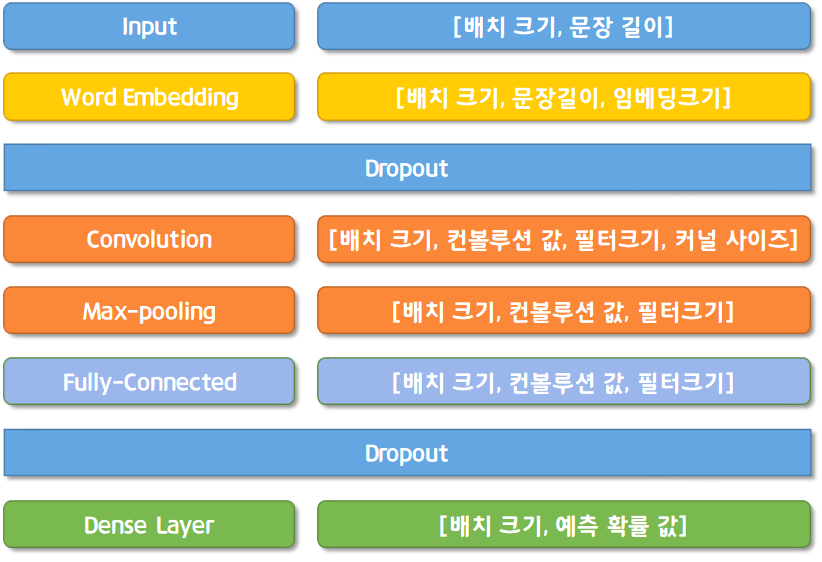
이 아키텍처를 바탕으로 모델을 구현해보자.
import sys
import os
import numpy as np
import json
from sklearn.model_selection import train_test_split
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing import sequence
DATA_IN_PATH = './data_in/'
DATA_OUT_PATH = './data_out/'
TRAIN_INPUT_DATA = 'train_input.npy'
TRAIN_LABEL_DATA = 'train_label.npy'
TEST_INPUT_DATA = 'test_input.npy'
TEST_ID_DATA = 'test_id.npy'
DATA_CONFIGS = 'data_configs.json'
train_input_data = np.load(open(DATA_IN_PATH + TRAIN_INPUT_DATA, 'rb'))
train_label_data = np.load(open(DATA_IN_PATH + TRAIN_LABEL_DATA, 'rb'))
test_input_data = np.load(open(DATA_IN_PATH + TEST_INPUT_DATA, 'rb'))
with open(DATA_IN_PATH + DATA_CONFIGS, 'r') as f:
prepro_configs = json.load(f)
print(prepro_configs.keys())먼저 필요한 라이브러리와 학습에 필요한 학습 및 평가 데이터를 불러온다.
다음으로 학습에 필요한 파라미터를 지정하고, 학습데이터와 검증 데이터를 나눈다.
# 파라메터 변수
RNG_SEED = 1234
BATCH_SIZE = 16
NUM_EPOCHS = 3
VOCAB_SIZE = prepro_configs['vocab_size'] + 1
EMB_SIZE = 128
VALID_SPLIT = 0.2
train_input, eval_input, train_label, eval_label = train_test_split(train_input_data, train_label_data, test_size=VALID_SPLIT, random_state=RNG_SEED)마지막으로 전처리 학습을 위해 tf.data를 설정한다.
def mapping_fn(X, Y=None):
input, label = {'x': X}, Y
return input, label
def train_input_fn():
dataset = tf.data.Dataset.from_tensor_slices((train_input, train_label))
dataset = dataset.shuffle(buffer_size=len(train_input))
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.map(mapping_fn)
dataset = dataset.repeat(count=NUM_EPOCHS)
iterator = dataset.make_one_shot_iterator()
return iterator.get_next()
def eval_input_fn():
dataset = tf.data.Dataset.from_tensor_slices((eval_input, eval_label))
dataset = dataset.shuffle(buffer_size=len(eval_input))
dataset = dataset.batch(BATCH_SIZE)
dataset = dataset.map(mapping_fn)
iterator = dataset.make_one_shot_iterator()
return iterator.get_next()이제 모델을 구현해보자.
def model_fn(features, labels, mode):
TRAIN = mode == tf.estimator.ModeKeys.TRAIN
EVAL = mode == tf.estimator.ModeKeys.EVAL
PREDICT = mode == tf.estimator.ModeKeys.PREDICT
embedding_layer = keras.layers.Embedding(
VOCAB_SIZE,
EMB_SIZE)(features['x'])
dropout_emb = keras.layers.Dropout(rate=0.5)(embedding_layer)
conv1 = keras.layers.Conv1D(
filters=128,
kernel_size=3,
padding='valid',
activation=tf.nn.relu)(dropout_emb)
pool1 = keras.layers.GlobalMaxPool1D()(conv1)
conv2 = keras.layers.Conv1D(
filters=128,
kernel_size=4,
padding='valid',
activation=tf.nn.relu)(dropout_emb)
pool2 = keras.layers.GlobalMaxPool1D()(conv2)
conv3 = keras.layers.Conv1D(
filters=128,
kernel_size=5,
padding='valid',
activation=tf.nn.relu)(dropout_emb)
pool3 = keras.layers.GlobalMaxPool1D()(conv3)
concat = keras.layers.concatenate([pool1, pool2, pool3])
hidden = keras.layers.Dense(250, activation=tf.nn.relu)(concat)
dropout_hidden = keras.layers.Dropout(rate=0.5)(hidden)
logits = keras.layers.Dense(1, name='logits')(dropout_hidden)
logits = tf.squeeze(logits, axis=-1)
if PREDICT:
return tf.estimator.EstimatorSpec(
mode=mode,
predictions={
'prob': tf.nn.sigmoid(logits)
}
)
loss = tf.losses.sigmoid_cross_entropy(labels, logits)
if EVAL:
pred = tf.nn.sigmoid(logits)
accuracy = tf.metrics.accuracy(labels, tf.round(pred))
return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops={'acc': accuracy})
if TRAIN:
global_step = tf.train.get_global_step()
train_op = tf.train.AdamOptimizer(0.001).minimize(loss, global_step)
return tf.estimator.EstimatorSpec(mode=mode, train_op=train_op, loss = loss)모델 자체는 이전에 생성한 순환 신경망과 거의 유사하다.
합성곱 연산의 경우 케라스 모듈 중 Conv1D를 활용하여 진행하며, 총 3개의 합성곱 층을 사용한다.
3개의 합성곱의 필터 크기는 각각 3, 4, 5로 다 다르게 하여 적용한다.
마지막으로 합성곱 층 출력값을 하나로 합친다.
또한 각 합성곱 신경망 이후에 맥스 풀링 층을 적용한다.
이렇게 생성된 모델 함수를 적용하여 에스티메이터 객체를 생성한다.
model_dir = os.path.join(os.getcwd(), "data_out/checkpoint/cnn/")
os.makedirs(model_dir, exist_ok=True)
config_tf = tf.estimator.RunConfig(save_checkpoints_steps=200, keep_checkpoint_max=2,
log_step_count_steps=400)
cnn_est = tf.estimator.Estimator(model_fn, model_dir=model_dir, config=config_tf)
cnn_est.train(train_input_fn) #학습하기
cnn_est.evaluate(eval_input_fn) #평가하기결과 :
{'acc': 0.8778, 'loss': 0.4738942, 'global_step': 3750}
앞서 진행했던 것과 동일하게 체크포인트를 저장할 경로와 모델 함수를 적용하여 객체를 생성한 후 모델을 학습하고 검증한다.
[마무리]
머신러닝 모델과 딥러닝 모델 두가지 모두 사용해본 결과, 딥러닝은 학습 시간이 머신러닝보다 훨씬 길고 구현이 어렵지만 캐글에 제출하였을 때의 점수를 보면 성능자체는 매우 우수한 모델임을 알 수 있다.
하지만 딥러닝이 항상 좋은 성과를 내는 것은 아니며, 보통 데이터의 수가 일정 이상 되는 경우에 성과가 좋다고 한다.
다음 포스팅부터는 영어가 아닌 한글에 대해 분류를 수행해보자!
'정리 > 텐서플로와 머신러닝으로 시작하는 자연어처리' 카테고리의 다른 글
| Chap04. 한글 텍스트 분류_모델링 2 (0) | 2021.08.03 |
|---|---|
| Chap04. 한글 텍스트 분류_모델링 1 (0) | 2021.08.02 |
| Chap04. 영어 텍스트 분류_모델링 2 (0) | 2021.07.29 |
| Chap04. 영어 텍스트 분류_모델링 1 (0) | 2021.07.26 |
| Chap04. 텍스트 분류_데이터전처리 실습 (0) | 2021.07.21 |



