영어와 한글은 언어적인 특성이 매우 달라서 전처리하는 과정부터 차이가 있다.
이번 포스팅에서는 한글 텍스트를 다루는 방법을 알아보고 분류하는 방법을 알아보도록 하자.
먼저, 이전에 사용한 NLTK는 한글 텍스트를 지원하지 않으며 한글 텍스트를 다루기 위해서는 KoNLPy를 사용해야 한다.
그러므로 KoNLPy를 사용해보자.
모델링을 위해 사용하는 데이터셋은 공개된 네이버 영화 리뷰 데이터를 사용한다.
이 데이터는 네이버 영화의 사용자 리뷰를 각 영화당 100개씩 모아서 만들어진 데이터로, 이 데이터를 사용하여 감정 분석을 수행해보자.
[ 데이터 전처리 및 분석 ]
데이터를 다운로드 한 후 데이터 파일을 살펴보자.
GitHub - e9t/nsmc: Naver sentiment movie corpus
Naver sentiment movie corpus. Contribute to e9t/nsmc development by creating an account on GitHub.
github.com
위의 주소로 들어가서 ratings.txt, ratins_train.txt, ratings_text.txt를 다운로드 받자.
▶ 데이터 불러오기 및 분석하기
데이터 다운로드가 완료되었다면 불러온 후 분석해보자.
영어 데이터를 가지고 진행했던 방식 그대로 데이터를 분석한 후 결과를 토대로 데이터 전처리를 진행한다.
먼저 필요한 라이브러리를 불러오자.
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
%matplotlib inline다음으로 불러올 데이터의 크기를 확인해보자.
DATA_IN_PATH = './data_in/'
print("파일 크기 : ")
for file in os.listdir(DATA_IN_PATH):
if 'txt' in file :
print(file.ljust(30) + str(round(os.path.getsize(DATA_IN_PATH + file) / 1000000, 2)) + 'MB')결과 :
파일 크기 :
ratings.txt 19.52MB
ratings_test.txt 4.89MB
ratings_train.txt 14.63MB
파일 크기를 확인한 결과 학습데이터 15만개, 평가데이터 5만개로 나눠진 것을 확인할 수 있다.
다음으로 판다스를 이용해 학습데이터를 확인해보자.
train_data = pd.read_csv(DATA_IN_PATH + 'ratings_train.txt', header = 0, delimiter = '\t', quoting = 3)
train_data.head()결과 :

데이터가 3개의 컬럼으로 이루어져 있으며, 각각 데이터의 인덱스, 리뷰내용, 긍정/부정을 나타내는 레이블 값을 나타내는 것을 확인하였다.
다음 데이터를 사용하여 데이터를 분석해보자.
print('전체 학습데이터의 개수: {}'.format(len(train_data)))결과 :
전체 학습데이터의 개수: 150000
위에서 말한대로 학습데이터는 15만개의 데이터로 구성되어 있는 것을 확인하였다.
이제 각 데이터에 대해 리뷰 길이를 확인해보자.
train_lenght = train_data['document'].astype(str).apply(len)
train_lenght.head()결과 :
0 19
1 33
2 17
3 29
4 61
Name: document, dtype: int64
결과를 보면 데이터의 길이는 19, 33, 17 등으로 이루어져 있다.
이제 이 변수를 사용해 전체 데이터에 대한 길이를 알아보자.
먼저, 히스토그램을 사용해보자.
# 그래프에 대한 이미지 사이즈 선언
# figsize: (가로, 세로) 형태의 튜플로 입력
plt.figure(figsize=(12, 5))
# 히스토그램 선언
# bins: 히스토그램 값들에 대한 버켓 범위
# range: x축 값의 범위
# alpha: 그래프 색상 투명도
# color: 그래프 색상
# label: 그래프에 대한 라벨
plt.hist(train_lenght, bins=200, alpha=0.5, color= 'r', label='word')
plt.yscale('log', nonposy='clip')
# 그래프 제목
plt.title('Log-Histogram of length of review')
# 그래프 x 축 라벨
plt.xlabel('Length of review')
# 그래프 y 축 라벨
plt.ylabel('Number of review')결과 :
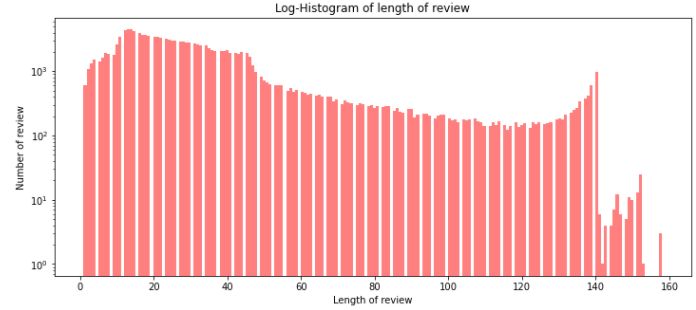
길이를 보면 매우 짧은 길이부터 140까지 고르게 분포되어 있는 것을 확인할 수 있다.
다음으로 통곗값을 계싼해보자.
print('리뷰 길이 최대 값: {}'.format(np.max(train_lenght)))
print('리뷰 길이 최소 값: {}'.format(np.min(train_lenght)))
print('리뷰 길이 평균 값: {:.2f}'.format(np.mean(train_lenght)))
print('리뷰 길이 표준편차: {:.2f}'.format(np.std(train_lenght)))
print('리뷰 길이 중간 값: {}'.format(np.median(train_lenght)))
# 사분위의 대한 경우는 0~100 스케일로 되어있음
print('리뷰 길이 제 1 사분위: {}'.format(np.percentile(train_lenght, 25)))
print('리뷰 길이 제 3 사분위: {}'.format(np.percentile(train_lenght, 75)))결과 :
리뷰 길이 최대 값: 158
리뷰 길이 최소 값: 1
리뷰 길이 평균 값: 35.24
리뷰 길이 표준편차: 29.58
리뷰 길이 중간 값: 27.0
리뷰 길이 제 1 사분위: 16.0
리뷰 길이 제 3 사분위: 42.0
다음으로 박스 플롯을 통해 확인해보자.
plt.figure(figsize=(12, 5))
# 박스플롯 생성
# 첫번째 파라메터: 여러 분포에 대한 데이터 리스트를 입력
# labels: 입력한 데이터에 대한 라벨
# showmeans: 평균값을 마크함
plt.boxplot(train_lenght,
labels=['counts'],
showmeans=True)결과 :
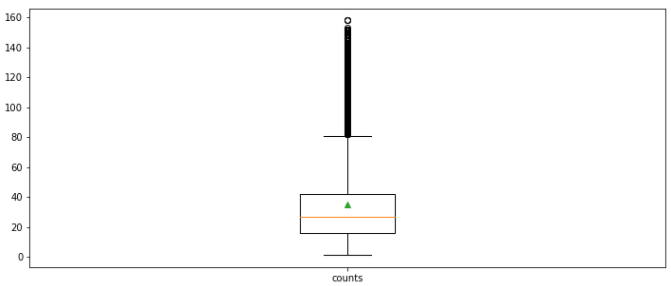
그림을 보면 일부 길이가 긴 데이터가 꽤 있다는 것을 확인할 수 있다.
중간값과 평균 값은 전체 데이터 중 아래쪽에 위치한다.
다음으로 자주 사용되는 어휘를 알아보자.
train_review = [review for review in train_data['document'] if type(review) is str]다음과 같이 리뷰 데이터를 워드 클라우드에 적용한다.
하지만 워드 클라우드는 기본적으로 영어 텍스트를 지원하는 라이브러리이기 때문에 한글 데이터를 넣으면 글자가 깨진다.
따라서 한글을 볼 수 있도록 한글 폰트를 설정해야 한다.
무료로 공개된 한글 폰트 중 아무거나 다운로드해서 './data_in'폴더로 옮겨놓자.
다음으로 워드 클라우드를 생성하고 설치한 폰트 설정 후 데이터를 적용하여 그래프를 그려보자.
wordcloud = WordCloud(font_path = DATA_IN_PATH + 'NanumGothic.ttf').generate(' '.join(train_review))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()결과 :

결과를 보면 '영화', '진짜', '정말' 등의 어휘가 가장 많이 사용됨을 알 수 있다.
다음으로 긍정, 부정을 나타내는 레이블 값의 비율을 확인해보자.
fig, axe = plt.subplots(ncols=1)
fig.set_size_inches(6, 3)
sns.countplot(train_data['label'])결과 :
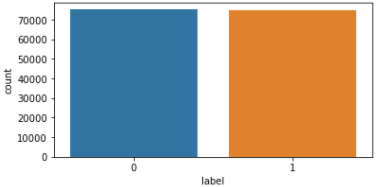
레이블은 긍정과 부정이 거의 반반씩 잘 분포됨을 확인할 수 있다.
다음으로 각 리뷰의 단어 수를 확인해보자.
먼저 각 데이터를 띄어쓰기 기준으로 나눈 후 개수를 하나의 변수로 할당하고, 그 값을 히스토그램으로 확인해보자.
train_word_counts = train_data['document'].astype(str).apply(lambda x:len(x.split(' ')))
plt.figure(figsize=(15, 10))
plt.hist(train_word_counts, bins=50, facecolor='r',label='train')
plt.title('Log-Histogram of word count in review', fontsize=15)
plt.yscale('log', nonposy='clip')
plt.legend()
plt.xlabel('Number of words', fontsize=15)
plt.ylabel('Number of reviews', fontsize=15)결과 :
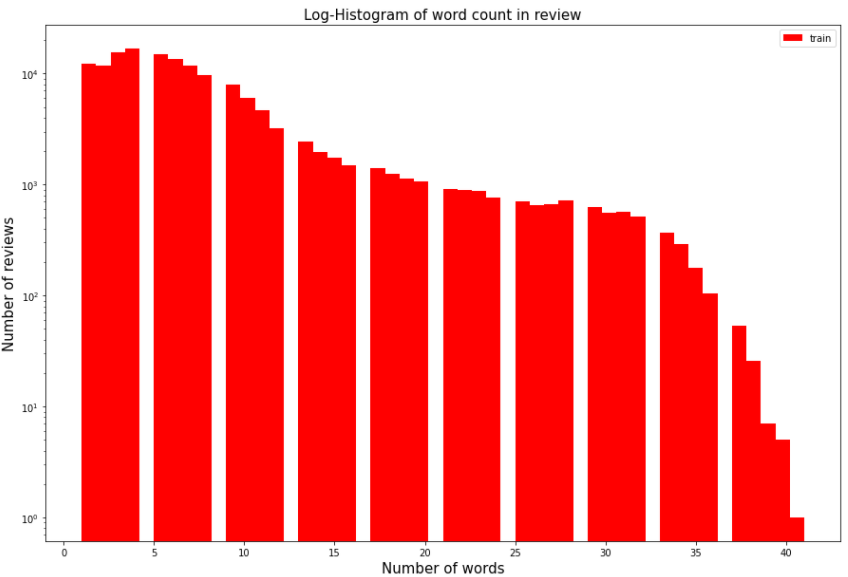
길이의 경우 대부분 5개 정도에 분포되어 있다.
그리고 이후로는 거의 고르게 분포되어 있으며 30개 이상의 데이터부터는 수가 급격히 줄어든다.
단어의 개수에 대한 통계삽을 확인해보자.
print('리뷰 단어 개수 최대 값: {}'.format(np.max(train_word_counts)))
print('리뷰 단어 개수 최소 값: {}'.format(np.min(train_word_counts)))
print('리뷰 단어 개수 평균 값: {:.2f}'.format(np.mean(train_word_counts)))
print('리뷰 단어 개수 표준편차: {:.2f}'.format(np.std(train_word_counts)))
print('리뷰 단어 개수 중간 값: {}'.format(np.median(train_word_counts)))
# 사분위의 대한 경우는 0~100 스케일로 되어있음
print('리뷰 단어 개수 제 1 사분위: {}'.format(np.percentile(train_word_counts, 25)))
print('리뷰 단어 개수 제 3 사분위: {}'.format(np.percentile(train_word_counts, 75)))결과 :
리뷰 단어 개수 최대 값: 41
리뷰 단어 개수 최소 값: 1
리뷰 단어 개수 평균 값: 7.58
리뷰 단어 개수 표준편차: 6.51
리뷰 단어 개수 중간 값: 6.0
리뷰 단어 개수 제 1 사분위: 3.0
리뷰 단어 개수 제 3 사분위: 9.0
리뷰당 평균 7~8개의 단어를 가지고 있으며 중간값은 6개 정도로 나타나 있다.
때문에 최대 단어 개수를 6개 또는 7로 설정할 수 있다.
마지막으로 각 데이터에 대해 특수문자 유무를 확인해보자.
qmarks = np.mean(train_data['document'].astype(str).apply(lambda x: '?' in x)) # 물음표가 구두점으로 쓰임
fullstop = np.mean(train_data['document'].astype(str).apply(lambda x: '.' in x)) # 마침표
print('물음표가있는 질문: {:.2f}%'.format(qmarks * 100))
print('마침표가 있는 질문: {:.2f}%'.format(fullstop * 100))결과 :
물음표가있는 질문: 8.25%
마침표가 있는 질문: 51.76%
리뷰 데이터 특성 상 물음표는 거의 없지만 마침표는 절반 정도의 데이터가 가지고 있음을 확인하였다.
이제 위에서 얻은 값을 통해 데이터를 전처리해보자.
▶ 데이터 전처리
먼저 전처리 과정에서 사용할 라이브러리를 불로오고 판다스의 데이터프레임 형태로 데이터를 불러오자.
import numpy as np
import pandas as pd
import re
import json
from konlpy.tag import Okt
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.preprocessing.text import Tokenizer
DATA_IN_PATH ='./data_in/'
train_data = pd.read_csv(DATA_IN_PATH + 'ratings_train.txt', header=0, delimiter='\t', quoting=3 )
print(train_data.head())결과 :

데이터를 보면 영어 리뷰와 달리 HTML태그가 보이지 않는다.
따라서 Beautiful Soup 라이브러리를 사용한 태그 제거는 따로 진행하지 않아도 된다.
하지만 특수문자나 숫자 등은 종종 보이기 때문에 이러한 전처리는 진행해줘야 한다.
먼저 정규표형식을 활용해 한글 문자가 아닌 것들을 모두 제거하자.
review_text = re.sub("[^가-힣ㄱ-ㅎㅏ-ㅣ\\s]", "", train_data['document'][0])
print(review_text)결과 :
아 더빙 진짜 짜증나네요 목소리
결과를 보면 특수문자가 모두 제거된 것을 확인하였다.
이제 불용어를 제거하기 위해 문장 단어로 나눈다.
이번에는 한글 텍스트 처리 라이브러리인 KoNLPy의 okt객체 형태소 분석기를 사용하여 분석해보자.
okt=Okt()
review_text = okt.morphs(review_text, stem=True)
print(review_text)결과 :
['아', '더빙', '진짜', '짜증나다', '목소리']
결과를 보면 형태소 분석기의 어간 추출을 통해 어간이 추출된 단어로 나뉘었으며, 짜증나네요가 짜증나다 처럼 정규화 된것을 확인할 수 있다.
이제 불용어를 제거해야 하는데 한글은 불용어가 따로 정의되어 있는 라이브러리가 없기 때문에 직접 불용어 사전을 만든 뒤 그 사전을 통해 제거해야한다.
stop_words = set(['은', '는', '이', '가', '하', '아', '것', '들','의', '있', '되', '수', '보', '주', '등', '한'])
clean_review = [token for token in review_text if not token in stop_words]
print(clean_review)결과 :
['더빙', '진짜', '짜증나다', '목소리']
불용어로 '은', '는', '이', '가' 등을 적었으며 결과에서는 '아'가 제거된 것을 볼 수 있다.
불용어까지 제거했다면 어느 정도 데이터가 정제되었다고 볼 수 있기 때문에 위의 과정들을 전체 데이터에 적용하도록 하나의 함수로 만들자.
def preprocessing(review, okt, remove_stopwords = False, stop_words = []):
# 함수의 인자는 다음과 같다.
# review : 전처리할 텍스트
# okt : okt 객체를 반복적으로 생성하지 않고 미리 생성후 인자로 받는다.
# remove_stopword : 불용어를 제거할지 선택 기본값은 False
# stop_word : 불용어 사전은 사용자가 직접 입력해야함 기본값은 비어있는 리스트
# 1. 한글 및 공백을 제외한 문자 모두 제거.
review_text = re.sub("[^가-힣ㄱ-ㅎㅏ-ㅣ\\s]", "", review)
# 2. okt 객체를 활용해서 형태소 단위로 나눈다.
word_review = okt.morphs(review_text, stem=True)
if remove_stopwords:
# 불용어 제거(선택적)
word_review = [token for token in word_review if not token in stop_words]
return word_review한글을 제외한 모든 무자 제거, 형태소 토크나이징, 불용어 제거 순으로 진행되는 함수를 만들었다.
이제 객체를 생성하고 불용어 사전을 정의한 후 함수를 실행하면 된다.
stop_words = [ '은', '는', '이', '가', '하', '아', '것', '들','의', '있', '되', '수', '보', '주', '등', '한']
okt = Okt()
clean_train_review = []
for review in train_data['document']:
# 비어있는 데이터에서 멈추지 않도록 string인 경우만 진행
if type(review) == str:
clean_train_review.append(preprocessing(review, okt, remove_stopwords = True, stop_words=stop_words))
else:
clean_train_review.append([]) #string이 아니면 비어있는 값 추가평가 데이터도 같이 진행한다.
test_data = pd.read_csv(DATA_IN_PATH + 'ratings_test.txt', header=0, delimiter='\t', quoting=3 )
clean_test_review = []
for review in test_data['document']:
# 비어있는 데이터에서 멈추지 않도록 string인 경우만 진행
if type(review) == str:
clean_test_review.append(preprocessing(review, okt, remove_stopwords = True, stop_words=stop_words))
else:
clean_test_review.append([]) #string이 아니면 비어있는 값 추가이제 학습 데이터와 평가 데이터에 대해 인덱스 벡터로 바꾼 후 패딩 처리를 해준다.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(clean_train_review)
train_sequences = tokenizer.texts_to_sequences(clean_train_review)
test_sequences = tokenizer.texts_to_sequences(clean_test_review)
word_vocab = tokenizer.word_index # 단어 사전 형태
MAX_SEQUENCE_LENGTH = 8 # 문장 최대 길이
train_inputs = pad_sequences(train_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post') # 학습 데이터를 벡터화
train_labels = np.array(train_data['label']) # 학습 데이터의 라벨
test_inputs = pad_sequences(test_sequences, maxlen=MAX_SEQUENCE_LENGTH, padding='post') # 테스트 데이터를 벡터화
test_labels = np.array(test_data['label']) # 테스트 데이터의 라벨최대 길이를 8로 지정하고 처리도니 데이터를 모델링 과정에서 사용할 수 있게 저장해두자.
DATA_IN_PATH = './data_in/'
TRAIN_INPUT_DATA = 'nsmc_train_input.npy'
TRAIN_LABEL_DATA = 'nsmc_train_label.npy'
TEST_INPUT_DATA = 'nsmc_test_input.npy'
TEST_LABEL_DATA = 'nsmc_test_label.npy'
DATA_CONFIGS = 'data_configs.json'
data_configs = {}
data_configs['vocab'] = word_vocab
data_configs['vocab_size'] = len(word_vocab) # vocab size 추가
import os
# 저장하는 디렉토리가 존재하지 않으면 생성
if not os.path.exists(DATA_IN_PATH):
os.makedirs(DATA_IN_PATH)
# 전처리 된 학습 데이터를 넘파이 형태로 저장
np.save(open(DATA_IN_PATH + TRAIN_INPUT_DATA, 'wb'), train_inputs)
np.save(open(DATA_IN_PATH + TRAIN_LABEL_DATA, 'wb'), train_labels)
# 전처리 된 테스트 데이터를 넘파이 형태로 저장
np.save(open(DATA_IN_PATH + TEST_INPUT_DATA, 'wb'), test_inputs)
np.save(open(DATA_IN_PATH + TEST_LABEL_DATA, 'wb'), test_labels)
# 데이터 사전을 json 형태로 저장
json.dump(data_configs, open(DATA_IN_PATH + DATA_CONFIGS, 'w'), ensure_ascii=False)이제 전처리 과정이 모두 끝났다.
다음 포스팅에서 이 데이터들을 가지고 모델링 실습을 진행하도록 하자.
'데이터 분석 & AI > 텐서플로와 머신러닝으로 시작하는 자연어처리' 카테고리의 다른 글
| Chap04. 한글 텍스트 분류_모델링 2 (0) | 2021.08.03 |
|---|---|
| Chap04. 영어 텍스트 분류_모델링 3 (0) | 2021.07.29 |
| Chap04. 영어 텍스트 분류_모델링 2 (0) | 2021.07.29 |
| Chap04. 영어 텍스트 분류_모델링 1 (0) | 2021.07.26 |
| Chap04. 텍스트 분류_데이터전처리 실습 (0) | 2021.07.21 |



